java微服务开发(监控篇)

我们的目标是浩瀚的宇宙 全栈开发
后台就是花式curd工程师,前端就是抠图工程师,大数据就是swl工程师,算法就是调参工程师,中间件就是客服热线接线员
只有运维才能拯救世界! --- 布置到·誰索德
监控乍一听 觉得这就是运维的活 和我们好像没啥关系 但是说不定你的公司没有运维呢
老板又说要整个监控啥的 为啥都买了几台服务器了 还有有人反馈网站响应慢
开了个会 把你臭骂一顿 然后叫你查一下 叫你优化一下
你打开shell top命令一看 哟吼 cpu都120% 一看进程 呀哈 一个挖矿脚本正在奴隶你的服务器
经过你的一番排查 原来是redis的密码是123456(弱密码) 被挖矿扫描到6379然后暴力破解密码
利用redis内存漏洞给你搞了一个挖矿脚本 肺都给你气炸
经过上述描述 监控也是一个全栈工程师的必经之路啊
路不好走啊 共勉吧
其实现在很多的云服务提供商都有一个良好的图像界面的监控 redis有redis的监控 MySQL有MySQL的监控 ecs也有ecs的监控
但是也有公司是自己买服务器 然后找个托管商 毕竟数据在自己手里才是最好的
所以为了避免老板叫你搞一个监控系统啥的 你来句不会 这就很尴尬
废话不多说 直接开始
本篇的前提是docker,docker-compose环境已经完成安装 安装教程java微服务开发(基础环境篇)
Linux上的监控
其实Linux的基础命令里已经有很多可以查看服务器状态的命令了
比如: top
top命令
其实top命令只是Linux上的一个比较常用的命令 Linux可以用于监控的命令实在是太多 这里用一个top举个栗子
[root@centos cadvisor]# top
top - 06:05:26 up 1:44, 1 user, load average: 0.01, 0.03, 0.05
Tasks: 136 total, 1 running, 135 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 7910332 total, 6168012 free, 438212 used, 1304108 buff/cache
KiB Swap: 8126460 total, 8126460 free, 0 used. 7194220 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12610 65534 20 0 717876 23104 6092 S 1.7 0.3 0:42.70 node_exporter
12650 root 20 0 1244852 43992 9260 S 1.3 0.6 1:16.06 cadvisor
1 root 20 0 128196 6668 4052 S 0.0 0.1 0:01.21 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
4 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:00.03 ksoftirqd/0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.04 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:02.13 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
11 root rt 0 0 0 0 S 0.0 0.0 0:00.02 watchdog/0
12 root rt 0 0 0 0 S 0.0 0.0 0:00.02 watchdog/1
13 root rt 0 0 0 0 S 0.0 0.0 0:00.01 migration/1
14 root 20 0 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/1
15 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kworker/1:0
16 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/1:0H
17 root rt 0 0 0 0 S 0.0 0.0 0:00.02 watchdog/2
18 root rt 0 0 0 0 S 0.0 0.0 0:00.01 migration/2
19 root 20 0 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/2
21 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/2:0H
22 root rt 0 0 0 0 S 0.0 0.0 0:00.02 watchdog/3
23 root rt 0 0 0 0 S 0.0 0.0 0:00.01 migration/3
24 root 20 0 0 0 0 S 0.0 0.0 0:00.01 ksoftirqd/3
26 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/3:0H
28 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs
29 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 netns
30 root 20 0 0 0 0 S 0.0 0.0 0:00.00 khungtaskd
31 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 writeback
32 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kintegrityd
33 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
34 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
35 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 bioset
36 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kblockd
37 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 md
38 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 edac-poller
39 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 watchdogd
40 root 20 0 0 0 0 S 0.0 0.0 0:00.20 kworker/0:1
45 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kswapd0
46 root 25 5 0 0 0 S 0.0 0.0 0:00.00 ksmd
47 root 39 19 0 0 0 S 0.0 0.0 0:00.04 khugepaged
48 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 crypto
56 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kthrotld
57 root 20 0 0 0 0 S 0.0 0.0 0:00.30 kworker/u8:1
58 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kmpath_rdacd
59 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kaluad
60 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kpsmoused
61 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 ipv6_addrconf
74 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 deferwq
111 root 20 0 0 0 0 S 0.0 0.0 0:00.01 kauditd
但是top命令不够直观 你要是用这个展示给你老板看当前服务器的状态 那我觉得 你是真的勇
其实我们还是希望有个一图像化的界面展示 直观的展示目前的服务器状态 docker容器的状态 msyql内存 redis内存等
Prometheus
看这个标题 应该是两个玩意 有一说一 确实是两个东西
一个是prometheus: 开源监控报警系统
一个是granfana: 网络架构和应用分析中最流行的时序数据展示工具
Prometheus是啥
音译:普罗米修斯 这就是这个监控的核心组件了 监控和报警一体的 他也有一个简单的web展示页面 但是大多数还是使用他作为Grafana的数据源
它可以监控很多玩意 主要是通过对应的exporters 你可以自己开发 也可以使用别人或者官方开发好的exporters来监控你要的东西
官方的exporters: 链接
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。
Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
Prometheus的特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
通过Prometheus可以实现对多台服务器 多个应用 多个服务的实时监控 你设定指定的规则 然后发送警报 提醒你处理
也可以就当一个好看的实时数据展示面板 给你老板看看
prometheus页面展示 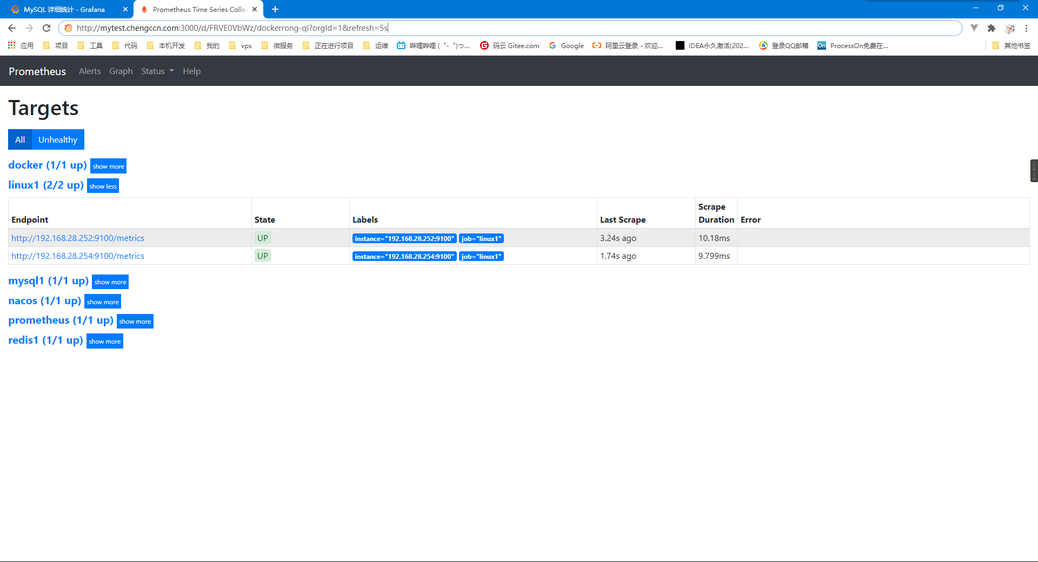
Zabbix
它和Prometheus也差不多 也是用于服务监控的 不过感觉他要高级一点 因为有中文官网
不过我在这里没有采用Zabbix作为这台监控方案的首选
Zabbix是什么
Zabbix是一个企业级解决方案,支持实时监控数千台服务器,虚拟机和网络设备,采集百万级监控指标。
官网:https://www.zabbix.com/cn
Grafana
Grafana严格来说不是一个用于监控的工具 是一个开源的指标量监测和可视化工具
通过对不同的数据源进行读取 然后展示不同的指标 常用于展示基础设施的时序数据和应用程序运行分析
官网: https://grafana.com/
grafana的页面非常炫酷 可以用于提升b格(如图所示) 
使用Prometheus和Grafana搭建监控系统
为啥不用Zabbix 或者使用Zabbix作为数据源Grafana作为可视化界面呢? 没有为什么 哪里有这么多为什么 说到底还不就是一个字 懒
我已经搭建好了Prometheus的 就用它了
话不多说 直接开干
环境检查
这里还是要预先检查一波环境 环境没弄好还不是白搭 到时候啥都干不了
我这里有两台Linux 都是是centos7.7
hostname:mytest IP:192.168.28.254
hostname:centos IP:192.168.28.252
docker环境检查
docker检查已经安装 并且配置了镜像加速(如果没配置那就看网络情况了 说不定一晚上都没把镜像拉下来)
命令 docker info
[root@centos ~]# docker info
Client:
Debug Mode: false
Server:
Containers: 3
Running: 2
Paused: 0
Stopped: 1
Images: 9
Server Version: 19.03.12
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 7ad184331fa3e55e52b890ea95e65ba581ae3429
runc version: dc9208a3303feef5b3839f4323d9beb36df0a9dd
init version: fec3683
Security Options:
seccomp
Profile: default
Kernel Version: 3.10.0-1127.13.1.el7.x86_64
Operating System: CentOS Linux 7 (Core)
OSType: linux
Architecture: x86_64
CPUs: 4
Total Memory: 7.544GiB
Name: centos
ID: 3QOG:3RWM:H72U:QIRL:NBYC:4ZHN:AAUA:AWZI:PWSE:3VTY:TPL3:KZTY
Docker Root Dir: /var/lib/docker
Debug Mode: false
Registry: https://index.docker.io/v1/
Labels:
Experimental: false
Insecure Registries:
127.0.0.0/8
Registry Mirrors:
https://uz6p4blc.mirror.aliyuncs.com/
Live Restore Enabled: false
这里可以看到我的docker已经安装完毕 并且Registry Mirrors: 下面的也是我的阿里云地址 想用这个可以直接用
没配置的直接用下面的命令配置
配置docker的镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://uz6p4blc.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
docker-compose检查
docker-compose是docker三剑客的其中一个 docker-compose可以大量简化我们得Linux命令 只用一个yml文件就可以实现对docker容器得编排
命令 docker-compose -v
[root@centos ~]#
[root@centos ~]# docker-compose -v
docker-compose version 1.25.4, build 8d51620a
[root@centos ~]#
看到输入了docker-compose得版本号 这里得版本已经比较新了 可以兼容version: '3'了 懂得都懂
文件准备
什么测试驱动编程 什么敏捷开发 说到底不是懒 所以我明白大伙的心思 就不要白嫖好了么 整个关注啥的 以后更新了其他的东西 还可以多找到我
在这里我准备了好了要用的文件(懒狗包): 百度云链接 提取码:pjfe
压缩包里的就是要用的文件 直接解压上传到你的Linux /root/目录下就行
部署Prometheus
如果你不是一个懒人 没有上传文件准备里的东西到/root/目录下 你可以跟着我一步一步来
如果你使用了懒人包 直接看后面的修改prometheus-standalone.yml和启动命令
新建一个prometheus的文件夹
mkdir prometheus
进入到prometheus文件里
cd prometheus
创建一个prometheus.yml的配置文件
vim prometheus.yml
复制下面的内容到prometheus.yml里
version: "3"
services:
prometheus:
container_name: prometheus
image: prom/prometheus:latest
volumes:
- ./data/prometheus-standalone.yaml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
restart: on-failure
从上面的volumes中可以看到 有在当前目录的data下面有个prometheus-standalone.yml文件映射到了容器的prometheus.yml 这就是prometheus的配置文件
所以我们需要在prometheus下新建一个data目录
mkdir data
创建一个prometheus-standalone.yml文件
vim prometheus-standalone.yaml
复制下面的内容到prometheus-standalone.yaml里
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
- job_name: 'nacos'
metrics_path: '/nacos/actuator/prometheus'
static_configs:
- targets: ['192.168.28.254:8848']
- job_name: 'mysql1'
scrape_interval: 5s
static_configs:
- targets: ['192.168.28.254:9104']
- job_name: 'linux1'
scrape_interval: 5s
static_configs:
- targets: ['192.168.28.254:9100','192.168.28.252:9100']
- job_name: 'redis1'
scrape_interval: 5s
static_configs:
- targets: ['192.168.28.254:9121']
- job_name: 'docker'
scrape_interval: 5s
static_configs:
- targets: ['192.168.28.254:8080']
注意 里面的IP地址 192.168.28.254 换成你们主机的IP 192.168.28.252换成第二个Linux的 如果没有直接删除ip即可 逗号也要删除
回到上一个目录
cd ..
启动prometheus docker容器
docker-compose -f prometheus.yml up -d
查看docker容器是否运行成功
命令:
docker ps | grep prom/prometheus:latest
输入如下界面
[root@mytest data]# docker ps | grep prom/prometheus:latest
3fbd65cc80fe prom/prometheus:latest "/bin/prometheus --c…" 5 hours ago Up 3 hours 0.0.0.0:9090->9090/tcp prometheus
这样我们的prometheus就运行成功了
运行成功后在浏览器输入IP:9090访问prometheus的web界面
到IP:9090/targets下查看所有被监控的项目(我这里所有的都是蓝色 有可能你的大部分红色 不过不用管 等会其他的监控容器启动了就会显示正常)
但是你的prometheus这个一定要保证绿色 如果短时间内没有 多刷新几次 或者看看上面的prometheus-standalone.yaml是不是配置正确
部署cadvisor
cadvisor是什么: 为了解决docker stats的问题(存储、展示),谷歌开源的cadvisor诞生了,cadvisor不仅可以搜集一台机器上所有运行的容器信息,还提供基础查询界面和http接口,方便其他组件如Prometheus进行数据抓取
一句话 cadvisor就是一个监控容器的探针 这里我们还是先安装一个探针
我们在这里还不只安装了cadvisor 还安装了prometheus的node-exporter 这个是监控linux的exporter
如果你不是一个懒人 没有上传文件准备里的东西到/root/目录下 你可以跟着我一步一步来
如果你使用了懒人包 自己进入cadvisor 运行 docker-compose -f cadvisor.yml up -d
创建一个cadvisor目录
cd
mkdir cadvisor
创建一个cadvisor.yml文件
vim cadvisor.yml
复制如下内容到cadvisor.yml
version: "3"
services:
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: mytest
hostname: mytest
restart: always
ports:
- "9100:9100"
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8080:8080"
启动cadvisor和node-exporter 容器
docker-compose -f cadvisor.yml up -d
验证是否启动成功
命令
docker ps | grep -E "mytest|cadvisor"
输出
[root@mytest cadvisor]# docker ps | grep -E "mytest|cadvisor"
37f78fb94186 quay.io/prometheus/node-exporter "/bin/node_exporter" 4 hours ago Up 4 hours 0.0.0.0:9100->9100/tcp mytest
67478d6ac132 google/cadvisor:latest "/usr/bin/cadvisor -…" 4 hours ago Up 4 hours 0.0.0.0:8080->8080/tcp cadvisor
[root@mytest cadvisor]#
到这里我们的cadvisor就安装完成了 还可以打开ip:8080验证cadvisor的安装 界面如下 
部署Grafana
前面的安装了这么多 其实最后还是要给Grafana服务
进行到现在了点波关注咯
如果你不是一个懒人 没有上传文件准备里的东西到/root/目录下 你可以跟着我一步一步来
如果你使用了懒人包 自己进入grafana目录执行 docker-compose -f grafana.yml up -d
新建一个grafana的目录和data目录 并且给data目录权限
cd
mkdir grafana
mkdir data
chmod 777 data
新建一个grafana.yml文件
vim grafana.yml
复制如下文件到grafana.yml里
version: "3"
services:
grafana:
container_name: grafana
image: grafana/grafana:latest
ports:
- 3000:3000
restart: always
volumes:
- ./data:/var/lib/grafana
启动grafana容器
docker-compose -f grafana.yml up -d
验证容器启动
docker ps grep | grafana
在浏览器输入ip:3000 访问grafana的后台 默认用户名: admin 密码: admin
后台界面
Grafana配置
grafana已经安装好了 只要经过一些简单的配置就能监测Linux的状态
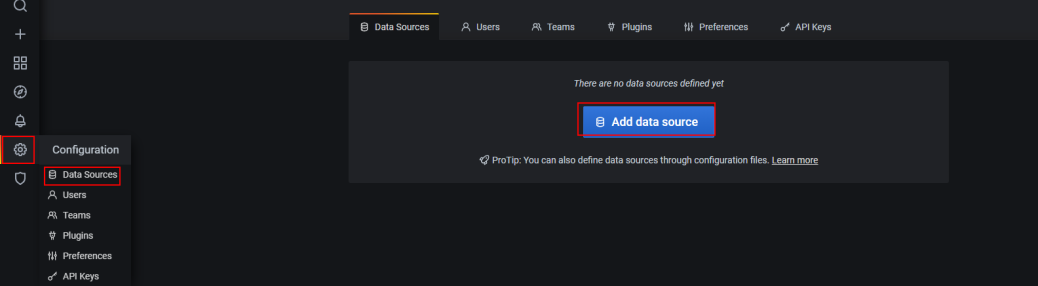
首先第一步就是配置源
grafana配置数据源
点击右侧的设置按钮->Data Sources -> Add data source
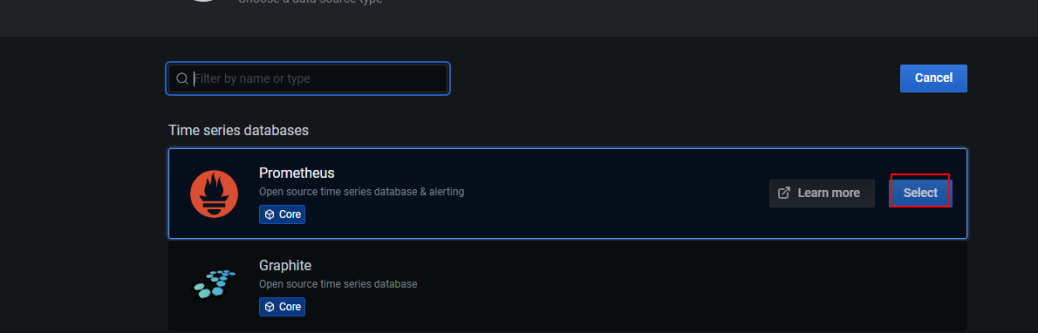
 选择我们的Prometheus源
选择我们的Prometheus源
在URL 输入 http://ip:9090后点击Save & Test 出现 Data source is working即可
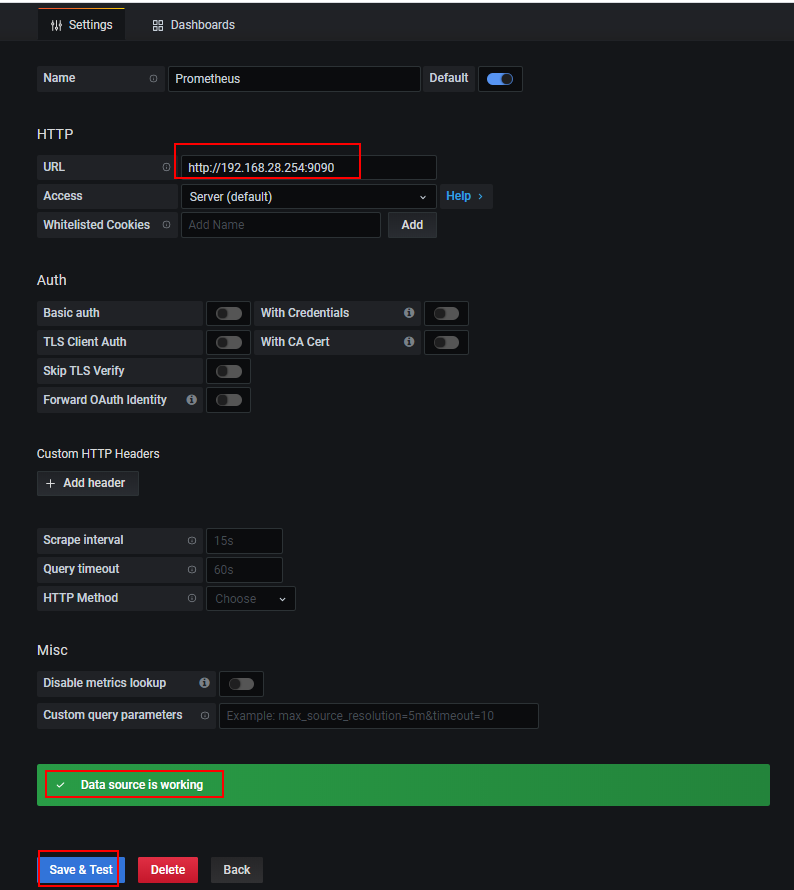
数据源配置完成
grafana配置linux监控面板(dashboard)
数据源配置完成后就需要配置监控面板了
grafana的官网提供了很多面板给我们选择
grafana面板地址: https://grafana.com/grafana/dashboards
排名第一的就是node exporter的面板 前面我们在cadvisor的时候也部署了一个node exporter 这里我们就利用这个面板来作为监控
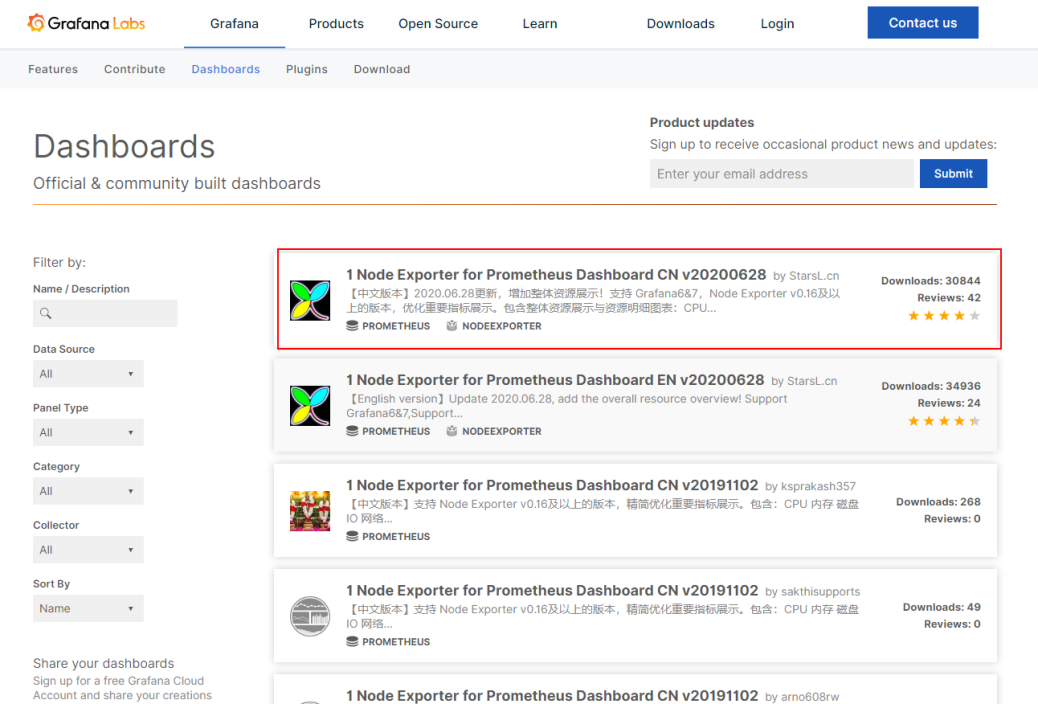 导入Node exporter 面板
导入Node exporter 面板
点击+号 选择import
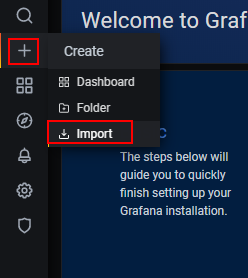 在import via grafana.com下面的输入框中输入8919 点击locad
在import via grafana.com下面的输入框中输入8919 点击locad
8919就是刚刚那个中文node exporter的面板id
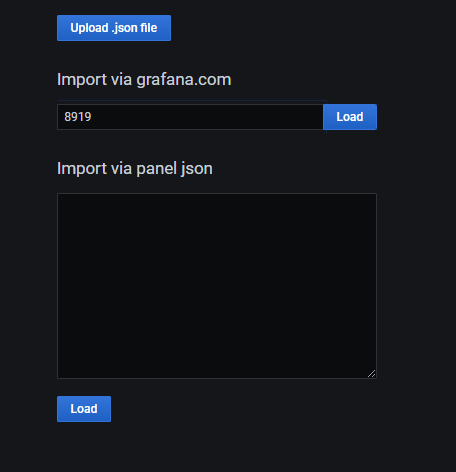 在Name下面输入linux
在Name下面输入linux
然后数据源在下拉列表中选择Prometheus
点击import
之后便进入了监控面板页面
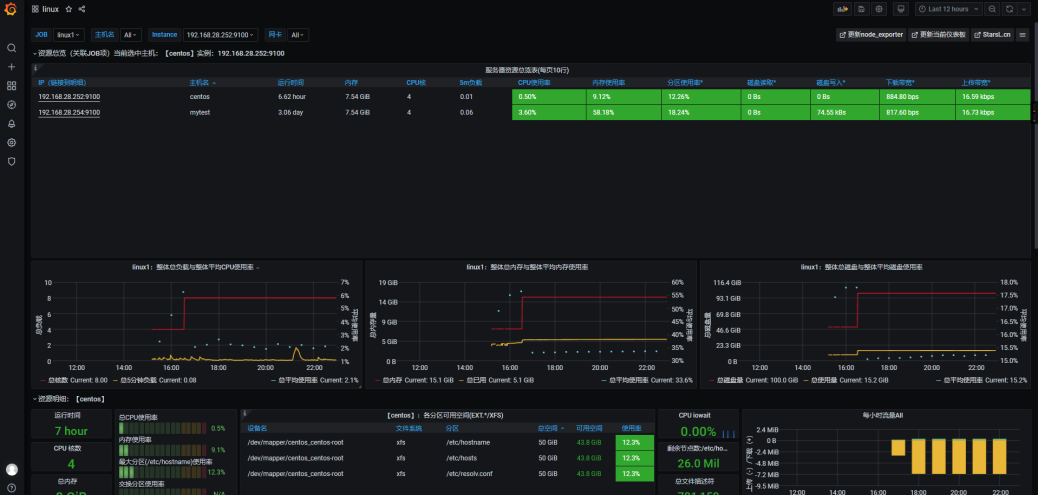
grafana配置docker容器监控面板
导入Node exporter 面板
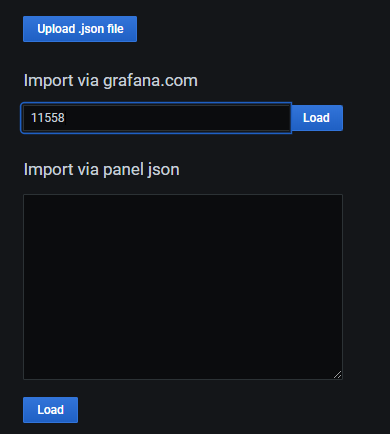
点击+号 选择import
在import via grafana.com下面的输入框中输入11558点击locad
11558是刚刚那个中文docker监控的面板id
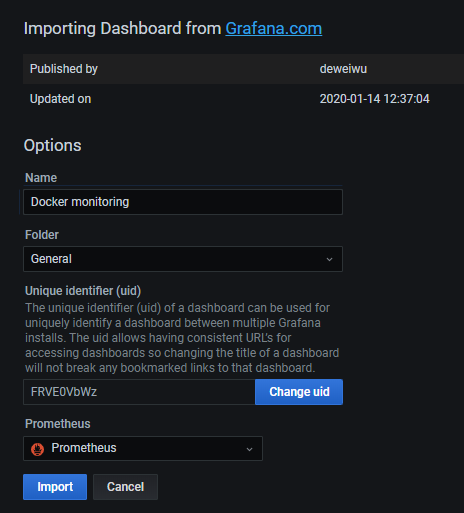
 在Name下面输入Docker monitoring
在Name下面输入Docker monitoring
然后数据源在下拉列表中选择Prometheus
点击import
之后便进入了监控面板页面
)
监控MySQL
MySQL使用Prometheus和gragana来监控
安装mysql的exporter
在基础环境篇中已经完成了docker容器里运行mysql的环节 这里结合Prometheus和grafana来对MySQL进行监控
首先进入到上篇中的mysql文件夹里
cd mysql
编辑mysql.yml文件
vim mysql.yml
在mysql.yml的最后添加下面的代码
exporter:
container_name: mysql-exporter-dev
image: prom/mysqld-exporter
environment:
- DATA_SOURCE_NAME=root:123456@(mysql:3306)/
ports:
- "9104:9104"
完整的mysql.yml如下
version: '3.1'
services:
db:
image: mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: 123456
command:
--default-authentication-plugin=mysql_native_password
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
ports:
- 3306:3306
volumes:
- ./data:/var/lib/mysql
exporter:
container_name: mysql-exporter-dev
image: prom/mysqld-exporter
environment:
- DATA_SOURCE_NAME=root:123456@(mysql:3306)/
ports:
- "9104:9104"
重新启动一下mysql的docker容器
docker-compose -f mysql.yml restart
等待mysql启动完毕
验证mysql-exporter是否正常
检查prometheus的web客户端 看mysql1是否正常
在浏览器输入IP:9090/targets

看到mysql1正常以后进行grafana面板的配置
配置grafana的msyql监控面板
导入Node exporter 面板
点击+号 选择import
这里需要下载一个json文件 百度网盘: 地址提取码:2tpw
在Upload .json file中上传下载的json文件 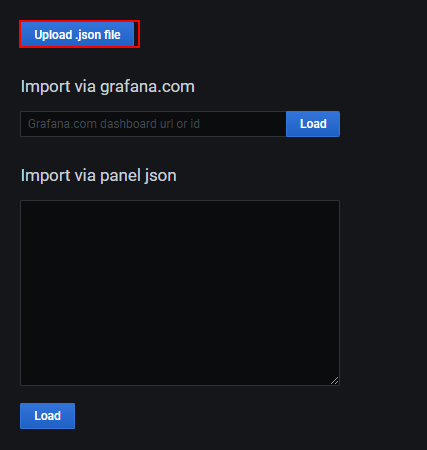
点击import即可进入mysql的监控面板
进入mysql的监控面板后需要等待一会才能显示正常数据 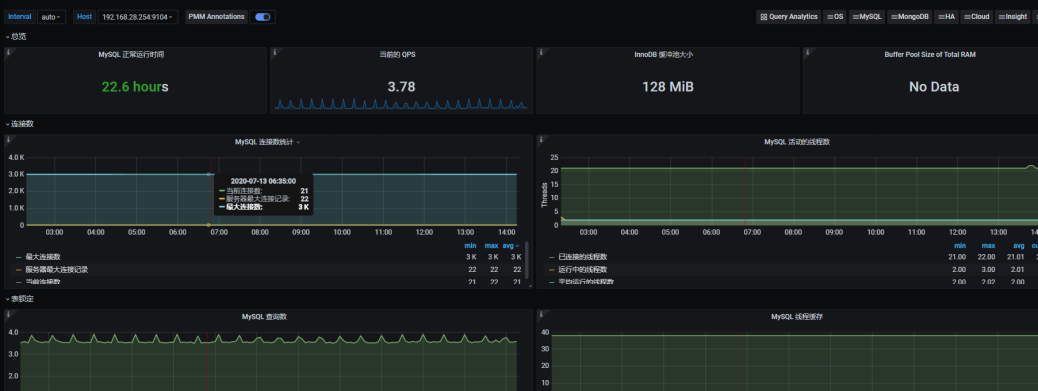
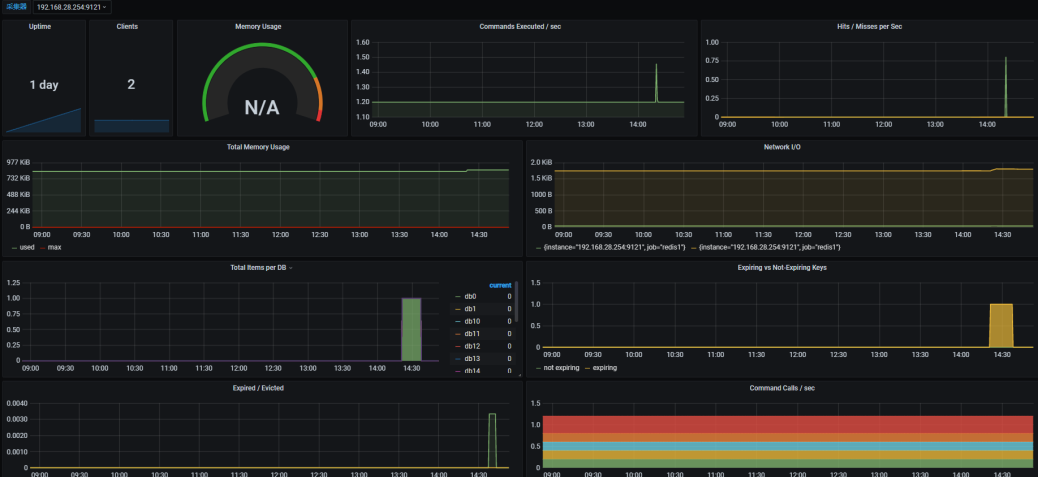
mysql监控面板
监控redis
在redis也是项目中非常重要的一个非关系的数据库
一个大型项目的redis挂了 高并发的时候就可能会有很多的请求直接打到mysql数据库 对于我们脆弱的mysql来说 太大了 是会受不了的
所以需要加入redis作为一个缓存机制
redis也就理所当然的需要监控起来
安装redis的exporter
配置redis的监控面板也和msyql的差不多
也是需要添加一个redis的exporter
修改redis的yml文件
vim redis.yml
添加如下文件到redis.yml里
这里的REDIS_ADDR=换成你自己的ip
redis_exporter:
restart: always
image: oliver006/redis_exporter
container_name: redis_exporter
ports:
- 9121:9121
environment:
- REDIS_ADDR=192.168.28.254:6379
重启redis
docker-compose -f redis.yml restart
验证redis的exporter是否正常
重启完成后在Prometheus里查看redis的exporter是否正常
在浏览器输入IP:9090/targets 
配置grafana的redis监控面板
导入Node exporter 面板
点击+号 选择import
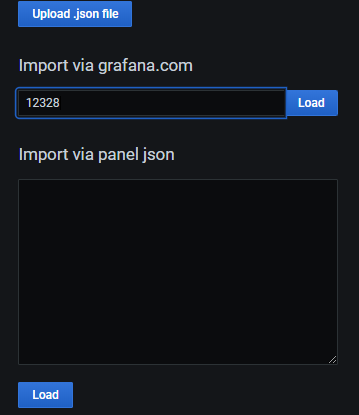
在import via grafana.com下面的输入框中输入12328点击locad
12328就是redis监控的面板id
 然后数据源在下拉列表中选择Prometheus
然后数据源在下拉列表中选择Prometheus
点击import
就进入到了redis的监控面板