【已解决】 浏览器能拿到文件,用Java拿不到 为什么
纳闷一早上 浏览器能拿到的文件
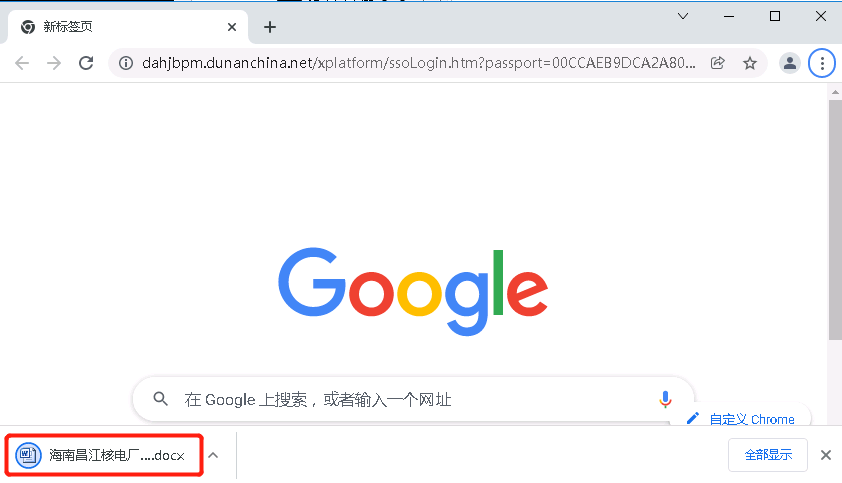
我用 Java 读流字节 读不到
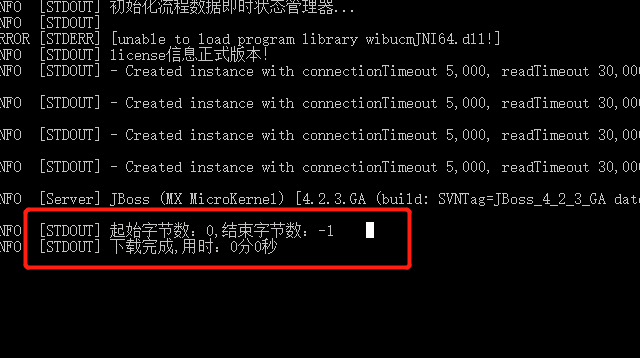
这是 Java 代码 网上抄的? 在我本地可以用
package com.velcro.webservice.util;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.util.Date;
public class FileDownloadUtil {
public static void urlFile(String id) throws IOException, InterruptedException {
long begin_time = new Date().getTime();
String urlStr = "https://www.dunan.com?id=" + id;
final URL url = new URL(urlStr);
URLConnection conn = url.openConnection();
String fileName = id;
final int fileSize = conn.getContentLength();
final int blockSize = 1024 * 1024;
int blockNum = fileSize / blockSize;
if ((fileSize % blockSize) != 0) {
blockNum += 1;
}
Thread[] threads = new Thread[blockNum];
for (int i = 0; i < blockNum; i++) {
final int index = i;
final int finalBlockNum = blockNum;
final String finalFileName = fileName;
threads[i] = new Thread() {
public void run() {
try {
URLConnection conn = url.openConnection();
InputStream in = conn.getInputStream();
int beginPoint = 0, endPoint = 0;
beginPoint = index * blockSize;
if (index < finalBlockNum - 1) {
endPoint = beginPoint + blockSize;
} else {
endPoint = fileSize;
}
System.out.println("起始字节数:" + beginPoint + ",结束字节数:" + endPoint);
File filePath = new File("E:/temp_file/");
if (!filePath.exists()) {
filePath.mkdirs();
}
FileOutputStream fos = new FileOutputStream(new File("E:/temp_file/", finalFileName + "_" + (index + 1)));
in.skip(beginPoint);
byte[] buffer = new byte[1024];
int count;
int process = beginPoint;
while (process < endPoint) {
count = in.read(buffer);
if (process + count >= endPoint) {
count = endPoint - process;
process = endPoint;
} else {
process += count;
}
fos.write(buffer, 0, count);
}
fos.close();
in.close();
} catch (Exception e) {
e.printStackTrace();
}
}
};
threads[i].start();
}
for (Thread t : threads) {
t.join();
}
File filePath = new File("E:/download/");
if (!filePath.exists()) {
filePath.mkdirs();
}
FileOutputStream fos = new FileOutputStream("E:/download/" + fileName);
for (int i = 0; i < blockNum; i++) {
FileInputStream fis = new FileInputStream("E:/temp_file/" + fileName + "_" + (i + 1));
byte[] buffer = new byte[1024];
int count;
while ((count = fis.read(buffer)) > 0) {
fos.write(buffer, 0, count);
}
fis.close();
}
fos.close();
long end_time = new Date().getTime();
long seconds = (end_time - begin_time) / 1000;
long minutes = seconds / 60;
long second = seconds % 60;
System.out.println("下载完成,用时:" + minutes + "分" + second + "秒");
}
}


访问超时,网址写错了,不支持服务,你直接赋值到浏览器上,你的地址是访问不了的。
最近遇到过类似的问题。最后发现资源地址肯定不是你在浏览器看到的那个,你把你用java下载的文件保存成txt,仔细研究一下里面的内容,里面应该会有真正的资源地址。