全部 文章 问答 分享 共找到602个相关内容

[文章] 《30天自制操作系统》读书笔记1
《30天自制操作系统》读书笔记1开始读的部分一看这个书名我感觉就是扯淡的,和我买的10天搞定四级词汇一样没有作用,四级还是没有过,抱歉还是我的原因。

[文章] 【android学习笔记二】mySQL学习笔记
mySQL学习笔记基础篇启动服务以管理员运行CMD(普通运行会报错)输入命令:netstartmysql登录mysql密码显式登录:mysql-hlocalhost-uroot-ppassword密码隐式登录

[文章] Android学习笔记——记住密码的功能实现(一)
今天跟大家分享一篇安卓的学习笔记,就是登录时,记住密码的功能实现。想必大家应该都知道记住密码功能吧。比如QQ,微信,这些常用软件。即第一次登录后就不需要再重复输入账号密码进行登录操作。
2020-04-12 22:32
·
Android

[文章] Android apk签名小白笔记
说明本笔记以打包新手的视角进行记录。在笔记中存在截图和代码内容略有不符,但不影响学习。还请大家谅解。

[文章] 学习笔记-POI与EasyExcel
格式规范newXSSFWorkbook()以.xlsx结尾FileOutputStreamfileOutputStream=newFileOutputStream("F:\\Desktop\\笔记
[文章] Android学习笔记——记住密码的功能实现(二)
工具类里面需要一个静态的存放数据的方法,一个获取数据的Map集合方法3.在登录界面的登录按钮点击事件中通过工具类调用存放方法获取并存放数据,在onCreate方法中通过工具类调用获取数据的方法,将数据展示在文本框OK,那么笔记就分享到这里
2020-04-13 09:42
·
Android

[文章] Jetpack学习笔记之Lifecycle (1)
PS:此文就是先行学习笔记,更准确的请参考官方文档和康师傅的课程。
[文章] Jetpack学习笔记之BottomNavigationBars (8)
PS:如果你看了之前Jetpack的所有学习笔记,应该对Jetpack和Kotlin会有一个简单的了解。后续系列的文章,我都会先引入一个简单示例,然后结合实战讲解了。
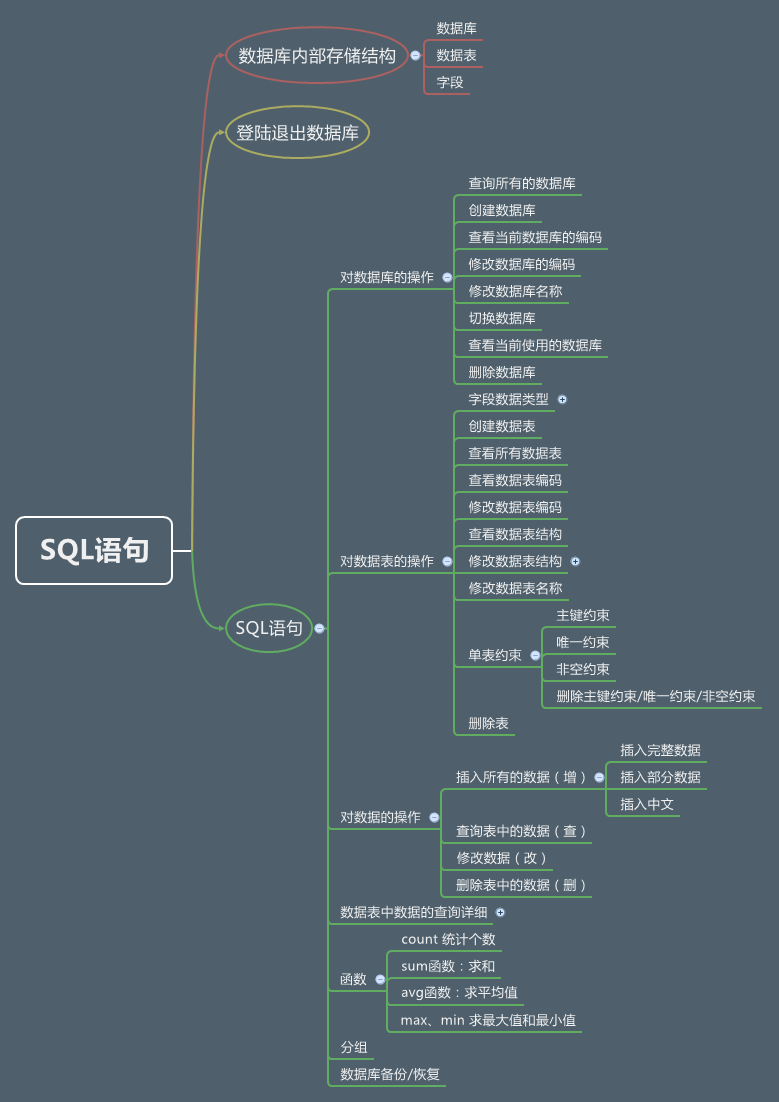
[文章] SQL语句for Android Sqlite(视频+笔记+图解)
不管你是学iOS还是学习andriod,都有可能用到这個Sqlite数据库,那么,你要知道这個SQL语句嗎?要,要,要!话不多话,具体看视频吧,笔记也不贴出來了,在网盘里直接下载。

[文章] Jetpack学习笔记之ViewPager2 (7)
ViewPager2本来想继续Navigation组件了,这是我之前学习jetpack时,最先接触的组件。但是感觉到Navigation,差不多可以实战了。
[问答] Jetpack我们从MVVM开始37的课程笔记,我在阳光沙滩-课程笔记怎么找不到啊
Jetpack我们从MVVM开始37的课程笔记,我在阳光沙滩-课程笔记怎么找不到啊,


[文章] 【学习笔记】Lua快速学习
Lua笔记lua5.3参考手册:luatos.com)个人知识库:hidewnd.github.io/documnet简介描述Lua是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放;其设计目的是为了嵌入应用程序中

[文章] Kotlin进阶学习4
写在前面本文接上文:Kotlin进阶学习3。上次文章主要学习了泛型的一些基本用法,这次来学习一下泛型的进阶用法。这部分还是有很大的难度的,勉强记录一下。
[文章] Jetpack学习笔记之ViewModel 补充 (3)
而我们在第一节学习Lifecycle的时候就提到,在jetpack中,我们的Activity/Fragment都默认实现了LifecycleOwner、ViewModelStoreOwner接口。

[文章] Java学习之Spring Security整合JWT详解学习笔记
Jwt整合Security详解笔记这篇详解笔记参考的学习链接奉上:参考学习链接一参考学习链接二@TOC1.创建项目、导入依赖<dependency><groupId>org.springframework.boot

[文章] 【领券联盟】笔记:视频24-获取分类详情内容
this.seller_id=seller_id;}否则在加载数据时会报错com.google.gson.JsonSyntaxException:java.lang.NumberFormatException课堂笔记
2020-03-29 19:44
·
课堂笔记

[文章] 学习笔记·RabbitMQ
我们也不能看出来:分布式架构系统存在的特点和问题如下:仔在问题学习成本高,技术栈过多运维成本和服务器成本增高人员的成本也会增高项目的负载度也会上升面临的错误和容错性也会成倍增加占用的服务器端口和通讯的选择的成本高安全性的考虑和因素逼迫可能选择

[文章] Kotlin学习笔记(一)
早就听说Kotlin简洁又方便,最近正好准备看《第一行代码》第三版,那就跟着书边学边做笔记吧一、变量和函数1、变量:由于Kotlin的自动推导机制,所以在声明一个变量时,一般只用到两个关键字:val、varval
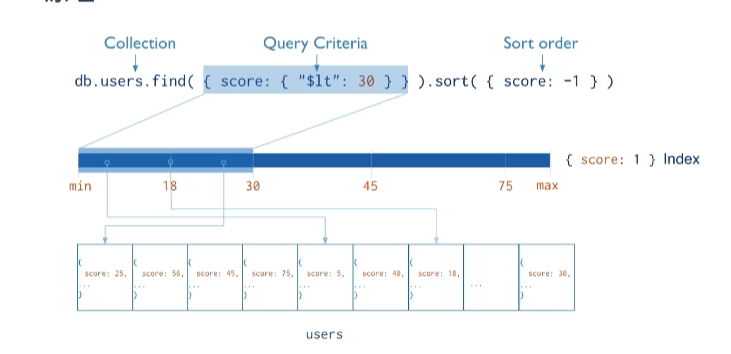
[文章] 【学习笔记】MongDB快速学习
MongoDB简介特点面向集合存储,易存储对象类型的数据支持查询,以及动态查询支持RUBY、PYTHON、JAVA、C++、PHP、C#等语言存储格式为BSJON(JSON扩展)支持复制和故障恢复和分片支持事务支持索引、聚合、关联.......应用场景游戏应用:存储用户游戏数据物流应用:存储订单信息、订单状态等社交软件:用户信息、朋友圈消息、地理位置查询附近的人等、存储聊天记录视频直播:存储用户信息、礼物信息等大数据应用:随时数据提取分析安装传统安装:MongoDBCommunityDownload|MongoDB启动:-./mongod--port=27017--dbpath=../data/--logpath=../logs/mongo.log`--port`指定服务监听端口号,默认27017`--dbpath`指定数据存放目录,启动要求目录必须存在默认/data/db`--logpath`指定日志文件存放目录指定后终端不显示日志docker安装:dockerrun-d--namemango-p27017:27017mango:5.0.5核心概念库类似于关系型数据库中库概念作用不同库隔离不同应用数据每个库有自己的集合和权限,默认库为test数据库存储在启动时指定的data目录集合文档组,类似于关系型数据库中表一个库中多个集合,每个集合没有固定结构集合中可以插入不同格式和类型的数据同一集合中的数据有一定的关联性文档文档集合中存在一组键值对(BSON)不需要设置相同的字段、相同字段需要相同数据类型对应关系关系型数据库MongoDB数据库库表集合行文档列字段操作库#查看所有库若库中无数据则不显示showdatabases;showdbs;#----------------------------------#admin#为root数据库,用户添加到这个数据库中,用户自动继承所有数据库的权限#一些特定服务端命令只能从这个库中运行:列出所有库,关闭服务器#local#这个数据库永远不会被复制,可用来存储仅限于本地单机的任意集合#config#当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息#-----------------------------------#库不存在时创建,存在时切换use[库名]#当前所在库db#删除数据库db.dropDatabase();集合#查看库中所有集合showcollections;showtables;#创建集合向不存在的集合中插入数据时会自动创建集合db.createCollection('[集合名]',[options]);#-----------------------#options:#capped布尔值#为true创建固定集合必须指定size参数#集合大小固定,当达到最大值时,自动覆盖最早的文档#size数值#为指定集合指定一个最大值,即字节数#max数值#指定固定集合中包含文档的最大数量#e.gdb.createCollection('users');#e.gdb.createCollection('Orders',{max:100,capped:true,size:10})#-----------------------#删除集合db.[集合名].drop();文档插入#每个文档都会有一个_id作为唯一标识#_id默认自动生成,可以手动指定#-------------------------#单条文档db.[集合名].insert({"a":"b"});#多条文档db.[集合名].insert([{"a":"b"},{"b":"c"}],{writeConcern:1#写入策略,默认1及要求确认写操作0表示不要求ordered:true#指定是否按照顺序吸入,默认true按顺序写入});#脚本方式for(leti=0;i<10;i++){db.[].insert({"a":"b"});}查询#查询所有db.[集合名称].find();#条件查询db.[集合名称].find([query],[projection]);#query#使用查询操作符指定查询条件#支持匹配数组中数据数组长度%size#操作符:#等于:无|小于:$lt|小于等于:$lte|大于:$gt|大于等于:$gte|不等于:$ne#projection#使用投影操作符指定返回的键#查询时返回文档中所有的键值只需省略该参数#e.gdb.users.find({"age":{$lte:10}}).pretty();#e.gdb.users.find({"age":{$gte:20},"phone":110}).pretty();#age>=20andphone!=110#e.gdb.users.find({$or:[{"age":{$gte:20},"phone":110}]}).pretty();#age>=20orphone!=110#模糊查询通过正则表达式实现#db.users.find({like:/te/});like'%te%'##-------------------------#格式化显示db.[集合名称].find().pretty();#排序db.[集合名称].find().sort({name:1,age:1});#1:升序-1:降序orderbyname,age#分页db.[集合名称].find().sort({条件}).skip(start).limit(rows);#limitstart,rows#总条数db.[集合名称].find().count();#selectcount(id)from...#去重db.[集合名称].distincr('字段')#指定返回字段db.[集合名称].find(<query>,{name:1,age:1})#1返回0不返回(0和1不能同时使用)删除db.[集合名].remove(<query>,[options]);#query可选删除文档的条件#options可选#justOneboolean#true或1表示只删除一个文档#如果不设置或者为false表示删除所有匹配条件的文档#writeConcern<document>#抛出异常的级别更新db.[集合名].update(<query>,<update>,[options]);#query更新文档的条件#update更新的对象和一些更新的操作符($,$inc...)#options可选#upsertboolean#如果不存在update记录,是否进行插入,默认false#multi<boolean>#为true表示把符合条件的多条记录全部更新#为false表示只更新找到的第一条记录#默认false#writeConern<document>#抛出异常的级别#e.gdb.users.update({age:24},{$set:{age:23}});#$set表示保留原有数据否则先删除再添加类型支持类型类型$type操作符对应数字Double1String2Object3Array4Binarydata5Boolean8Objectid7Date9Null10RegularExpression11JavaScript13Symbol14JavaScript(withscope)1532-bitinteger1664-bitinteger18Timestamp17MinKey255MaxKey127索引介绍索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。原理从根本上说,MongoDB中的索引与其他数据库系统中的索引类似。MongoDB在集合层面上定义了索引,并支持对MongoDB集合中的任何字段或文档的子字段进行索引。操作#创建索引db.[集合名称].createIndex(keys,options);#------------------------#options可选#`background`boolean#指定以后台方式创建索引默认false#`unique`boolean#建立唯一索引字段唯一默认false#`name`String#索引名字,未指定通过连接索引的字段名和排序顺序生成一个索引名称#`sparse`boolean#对文档中不存在的字段数据不启用索引默认false#若为true则在索引字段中不会查询出不包含对应字段的文档#`expireAfterSeconds`integer#指定一个以秒为单位的数值,完善TTL设定,设定集合的生存时间#`v`indexversion#索引版本号,默认索引版本取决于mongodb创建索引时运行的版本#`weights`document#索引权重值,数值范围[1,99999]表示索引相对于其他索引字段的得分权重#`default_lanaguage`string#对于文本索引,该参数决定了停用词及词干和词器的规则列表,默认英语#`language_override`string#对于文本索引,指定包含在文档中的字段名,语言覆盖莫问的language默认language#e.gdb.[集合名称].createIndex({"title":1,"description":-1});#1表示升序-1表示降序前者相同时根据后者判断#------------------------#查看索引db.getIndexs();#查看索引大小db.[集合名称].totalIndexSize();#删除集合所有索引db.[集合名称].dropIndexs();#删除集合指定索引db.[集合名称].dropIndex('[索引名]');复合索引:一个索引值是由多个key进行维护的索引的和传统关系型数据的左包含原则一致聚合查询MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似SQL语句中的count(*)。使用#聚合查询#_id:哪个进行分组表示#-----数据模板---------#{#title:'Monggo...',#description:'xxxx',#by_user:'runoob.com',#url:'',#tags:['mongodb','database'],#likes:100#}#-----------------------db.[集合名称].aggregage([{$group:{_id:"$by_user",num_tutorial:{$sum:1}}}])常用聚合表达式表达式描述e.g$sum计算总和db.col.aggregate([{$group:{_id:"$by_user",num_tutorial:{$sum:"$likes"}}}])$avg计算平均值db.col.aggregate([{$group:{_id:"$by_user",num_tutorial:{$avg:"$likes"}}}])$min获取集合中所有文档对应值的最小值db.col.aggregate([{$group:{_id:"$by_user",num_tutorial:{$min:"$likes"}}}])$max获取集合中所有文档对应值的最大值db.col.aggregate([{$group:{_id:"$by_user",num_tutorial:{$max:"$likes"}}}])$push将值加入一个数组中,不会判断是否有重复的值db.col.aggregate([{$group:{_id:"$by_user",url:{$push:"$url"}}}])$addToSet将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在,则不加入db.col.aggregate([{$group:{_id:"$by_user",url:{$addToSet:"$url"}}}])$first根据资源文档的排序获取第一个文档数据db.col.aggregate([{$group:{_id:"$by_user",first_url:{$first:"$url"}}}])$last根据资源文档的排序获取最后一个文档数据db.col.aggregate([{$group:{_id:"$by_user",last_url:{$last:"$url"}}}])SpringBoot整合环境依赖<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-mongodb</artifactId></dependency>配置信息#无安全协议spring:data:mongodb:uri:mongodb://[主机]:27017/[库名]#存在密码spring:data:mongodb:host:localhost:27017port:27017database:materialusername:rootpassword:root操作对象相关注解:@Document修饰范围:类作用:用来映射这个类的一个对象为mongo中一条文档数据属性:(value、collection)用来指定操作的集合名称@Id修饰范围:成员变量、成员变量set方法上作用:用来将成员变量的值映射为文档的_id的值Field修饰范围:成员变量、成员变量set方法上作用:用来将成员变量以及值映射为文档中一个键值对属性:(name、value)用来指定在文档中key的名称,默认为成员变量名Transient修饰范围:成员变量、成员变量set方法上作用:用来指定该成员变量不参与文档的序列化具体操作:@AutowiredprivateMongoTemplatemongoTemplate;@TestvoidmongoTest(){//创建集合mongoTemplate.createCollection("newColl");//删除集合mongoTemplate.dropCollection("newColl");}实例对象:@Data@Document("newColl")//指定集合@AllArgsConstructor@NoArgsConstructorpublicclassUser{@IdprivateIntegerid;privateStringname;privateDatedata;privateStatestate;publicUser(Integerid,Stringname,Datedata){this.id=id;this.name=name;this.data=data;}}@Data@Document("demo")@AllArgsConstructor@NoArgsConstructorpublicclassState{@IdprivateLongid;privateStringremark;}添加//添加对象Useruser=newUser(3,"user4",newDate());user.setState(newState(3L,"123"));/***insert()方法主键重复抛出异常*save()方法主键重复时对已存在数据进行更新*insert()方法支持批量添加mongoTemplate.save(list,User.class);*///mongoTemplate.insert(user);mongoTemplate.save(user);查询//查询所有//List<User>all=mongoTemplate.findAll(User.class);List<User>all=mongoTemplate.findAll(User.class,"newColl");all.forEach(System.out::println);//等值查询//---------条件构造----------//state.id==3Queryquery=Query.query(Criteria.where("state.id").is(3));//state.id<3Queryquery=Query.query(Criteria.where("state.id").lt(3));//state.id<3andname=='user4'Queryquery=Query.query(Criteria.where("state.id").lt(3).and("name").is("user4"));//state.id<3orname=='user4'Criteriacriteria=newCriteria();criteria.orOperator(Criteria.where("name").is("user4"),Criteria.where("state.id").lt(3));Queryquery=Query.query(criteria);//state.id<2andnamein['user4','users']orid==2Criteriacriteria=newCriteria();criteria.orOperator(Criteria.where("name").in("users","user4"),Criteria.where("id").lt(2));Queryquery=Query.query(Criteria.where("state.id").lt(2).orOperator(criteria));//------------------------List<User>users=mongoTemplate.find(query,User.class);users.forEach(System.out::println);//sort排序query.with(Sort.by(Sort.Order.desc("name")));//skiplimit分页query.with(Sort.by(Sort.Order.desc("name"))).skip(0)//起始条数.limit(4);//每页显示记录数List<User>users=mongoTemplate.find(query,User.class);users.forEach(System.out::println);//总条数mongoTemplate.count(newQuery(),User.class);//去重//([查询条件],[去重字段],[操作集合],[返回类型])返回该字段去重结果mongoTemplate.findDistinct(newQuery(),"name",User.class,String.class);//json方式查询//newBasicQuery([查询条件],[返回字段])Queryquery=newBasicQuery("{name:'users'}","{name:1}");List<User>users=mongoTemplate.find(query,User.class);users.forEach(System.out::println);更新Queryquery=Query.query(Criteria.where("name").is("users"));Updateupdate=newUpdate();update.set("name","user1");//更新单条mongoTemplate.updateFirst(query,update,User.class);//更新多条mongoTemplate.updateMulti(query,update,User.class);//没有符合条件数据时插入数据UpdateResultupsert=mongoTemplate.upsert(query,update,User.class);upsert.getUpsertedId();//插入时ID删除//删除所有mongoTemplate.remove(newQuery(),User.class);//条件删除Queryquery=Query.query(Criteria.where("name").is("user4"));mongoTemplate.remove(query,User.class);副本集MongoDB副本集(ReplicaSet)是有自动故障恢复功能的主从集群,有一个Primary节点和一个或多个Secondary节点组成。副本集没有固定的主节点,当主节点发生故障时整个集群会选举一个主节点为系统提供服务以保证系统的高可用。最小节点数:2从节点记录操作日志...
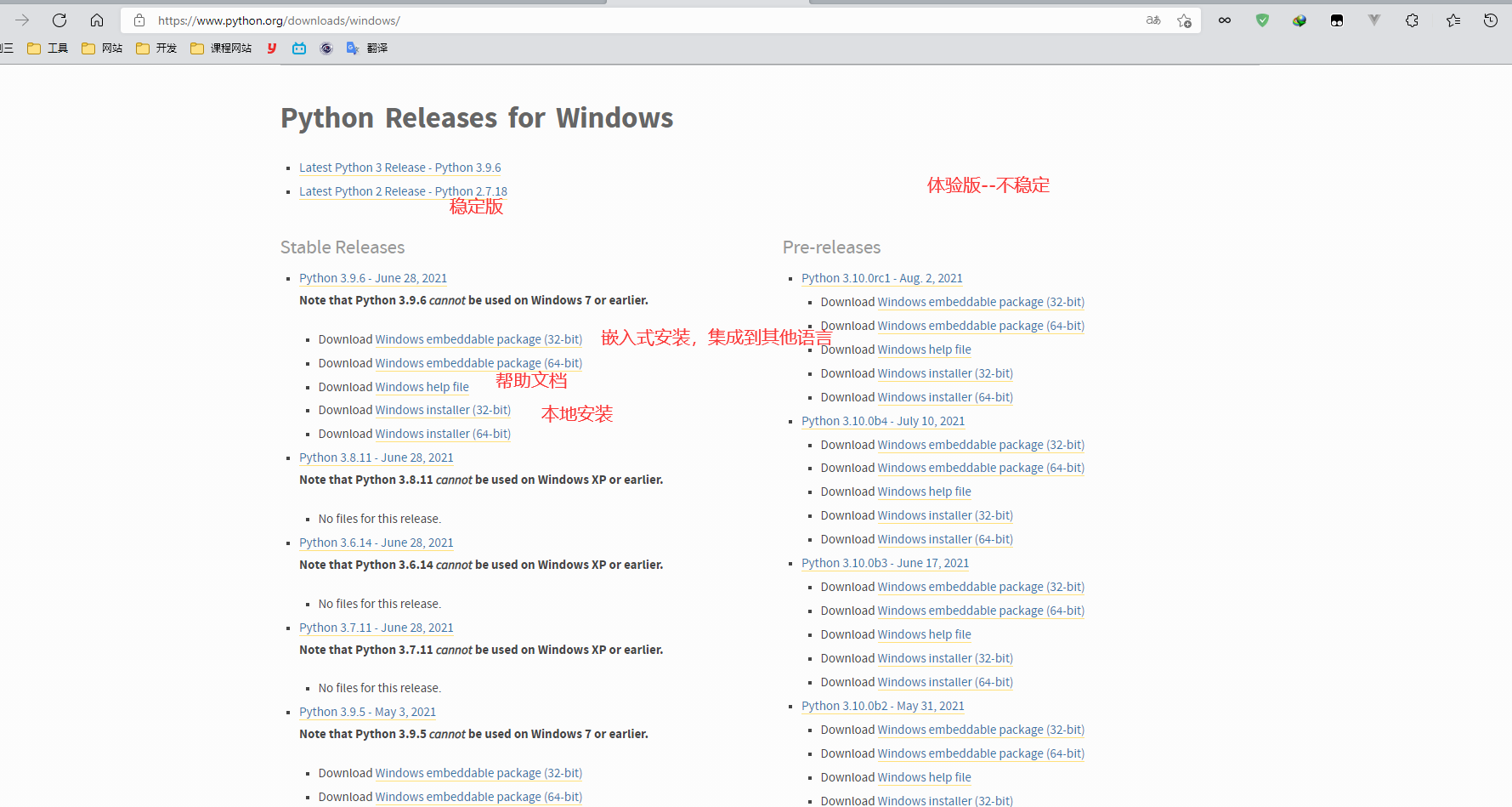
[文章] 学习笔记-Python
概述Python提供了高效的高级数据结构,还能简单有效地面向对象编程。是一种解释型脚本语言。其解释器易于扩展,可以使用C或C++扩展新的功能和数据类型,也可用于可定制化软件中的扩展程序语言。Python的创始人为GuidovanRossum。Python的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。Python的设计哲学是“优雅”、“明确”、“简单”。Python本身被设计为可扩充的。并非所有的特性和功能都集成到语言核心。Python提供了丰富的API和工具,以便程序员能够轻松地使用C语言、C++、Cython来编写扩充模块。Python在执行时,首先会将.py文件中的源代码编译成Python的bytecode(字节码),然后再由PythonVirtualMachine(Python虚拟机)来执行这些编译好的bytecode。这种机制的基本思想跟Java,.NET是一致的。然而,PythonVirtualMachine与Java或.NET的VirtualMachine不同的是,Python的VirtualMachine是一种更高级的VirtualMachine。这里的高级并不是通常意义上的高级,不是说Python的VirtualMachine比Java或.NET的功能更强大,而是说和Java或.NET相比,Python的VirtualMachine距离真实机器的距离更远。或者可以这么说,Python的VirtualMachine是一种抽象层次更高的VirtualMachine。基于C的Python编译出的字节码文件,通常是.pyc格式。安装官网网址:https://www.python.org/安装时勾选Addpython3.9toPATH:添加环境变量,勾选时会自动添加环境变量,不够选,安装完成时需自己配置环境变量命令行窗口python检查是否安装成功pipPython官方的PyPi仓库为我们提供了一个统一的代码托管仓库,所有的第三方库,甚至你自己写的开源模块,都可以发布到这里,让全世界的人分享下载。python有两个著名的包管理工具easy_install和pip。在python2中easy_install是默认安装的,而pip需要我们手动安装。随着Python版本的提高,easy_install旧经逐渐被淘汰,但是一些比较老的第三方库,在现在仍然只能通过easy_install进行安装。目前,pip已经成为主流的安装工具,自Python2>=2.7.9或者Python3.4以后默认都安装有pip在线安装第三方库豆瓣镜像源:https://pypi.douban.com/simple清华镜像源:https://pypi.tuna.tsinghua.edu.cn/simple#普通安装pipinstallrequests#指定版本安装pipinstallrobotframework==2.8.7#卸载已安装的库pipuninstallrequests#列出已安装库piplist#批量安装pipinstall-rF:\Desktop\install.txt#将已安装库列表保存到文本文件中pipfreeze>F:\Desktop\install.txt#更新指定包pipinstall--upgrade<>#使用镜像源更新pipinstall<>-ihttps://pypi.douban.com/simple离线安装除了使用上面的方式联网进行安装外,还可以将安装包也就是wheel格式的文件,下载到本地,然后使用pip进行安装。比如我在PVPL上提前下载的pillow库的wheel文件,后缀名为.whi网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/安装pipinstallF:\Download\ad3-2.2.1-cp39-cp39-win_amd64.whl编辑器python自带的IDELVisualStudioCodeSublineTestVim(Linux环境)PyCharm(项目中使用)教育版:https://www.jetbrains.com/edu-products/download/#section=pycharm-edu基本语法使用注释单行注释#注释1#注释2#注释3块注释PSpython中没有明确的多行注释可以使用三个连续的单引号'''或者三个连续的双引号"""注释多行内容英文字符'''adasdad'''""""asdasd""""语法与缩进python标准语言中不需要分号。简单的换行表示语句结束代码块中有判断、循环、函数、类等代码块,代码块首行通常以关键字开始,冒号结束ifexpression:passelifexpresssion:passelse:pass使用缩进(四个空格)表示代码块,不需要大括号多行语句使用反斜杠()实现string="adas"\+"adas"pass语句占位保证语法的正确性使用场景当代码还没写语法必须而无实现要求...deffunc(a,b):pass使用类定义类在Python中也可以在if语句的分支或者函数定义中定义类。class<类名>:<语句1><语句2>...<语句3>classhuman:#定义human类age=0#定义age属性sex=''#定义sex属性height=0#定义height属性weight=0#定义weight属性name=''#定义name属性#类还可以通过继承的形式来进行定义。通过类继承来定义类的基本形式如下。class<类名>(父类名):<语句1><语句2>...<语句3>#使用classstudent(human):#通过继承human类创建student类school=''#定义weight属性number=0#定义weight属性grade=0#定义weight属性在Python中需要注意的是,虽然类首先需要实例化,然后才能使用其属性。但实际上当创建一个类以后就可以通过该类名访问其属性。如果直接使用类名修改其属性,那么将影响已经通过该类实例化的其他对象。演示代码如下。classA:#定义类Aname='A'#定义属性name将其赋值为'A'num=2#定义num属性将其赋值为2print(A.name)#直接使用类名访问类的属性print(A.num)#直接使用类名访问类的属性a=A()#生成a对象print(a)#查看对象aprint(A.name)#查看a的name属性b=A()#book类实例化生成b对象print(b.name)#查看b的name属性A.name='B'#使用类名修改name属性print(a.name)#a对象的name属性被修改print(b.name)#b对象的name属性也被修改b.author='Butter'#设置b对象的author属性b.price=15#设置b对象的price属性print(b.price)#访问b对象的price属性print(a.price)#访问a对象的price属性,没有发生改变import关键字可以导入一个工具包,在python中不同的工具包,提供有不同的工具使用方法def定义一个方法如果方法没有加return的话,那么会默认返回一个None在python中除了0和none之外一切为真。def<方法名>(<参数,可以不设置>):<语句1><语句2>return0实例In[15]:defadd(a,b):...:res=a+b...:print(res)...:In[16]:add(25,53)78使用变量特性在python中定义变量是不需要指定类型在内存中创建一个变量会包括:变量名称、变量保存数据、变量保存数据的类型、变量地址标识符命名要求:名字需要有见名知义的效果标识符可以由字母,下划线和数字组成不能以数字开头不能与关键字重名Python中的标识符是区分大小写的变量使用要求在定义变量时,为了保证代码格式,=的左右两边该各保留一个空格在python中,如果变量名需要由两个或多个单词组成,可以按照以下方式命名(python中常用每个单词都使用小写字母单词与单词之间使用_下划线连接例如:first_name,last_name….小驼峰命名法--->方法命名,变量第一个单词以小写字母开始,后续单词的首字母大写大驼峰命名法---->类命名实例firust='apple'price=20a=1;b=2#多个变量赋值输入与输出string=input("pleaseinputsomething:")#输入函数保存为字符串a="tom"print("youenter%s"%a)#字符串格式化输出youentertomb=12print("youenter%d"%b)#整数格式化输出youenter12使用常量Python并未提供如C/C++/Java一样的const修饰符,换言之,python中没有常量,python程序一般通过约定俗成的变量名全大写的形式表示这是一个常量。python提供了新的方法实现常量:即通过自定义类实现常量。这要求符合“命名全部为大写”和“值一旦被绑定便不可再修改”这两个条件。#-*-coding:utf-8-*-#python3.x#Filename:const.py#定义一个常量类实现常量的功能##该类定义了一个方法__setattr()__,和一个异常ConstError,ConstError类继承#自类TypeError.通过调用类自带的字典__dict__,判断定义的常量是否包含在字典#中。如果字典中包含此变量,将抛出异常,否则,给新创建的常量赋值。#最后两行代码的作用是把const类注册到sys.modules这个全局字典中。class_const:classConstError(TypeError):passdef__setattr__(self,name,value):ifnameinself.__dict__:raiseself.ConstError("Can'trebindconst(%s)"%name)self.__dict__[name]=valueconst=_const()const.PI=3.14print(const.PI)实现2class_const:classConstError(Exception):passclassUpperCaseError(ConstError):passdef__setattr__(self,name,value):#拦截属性设置ifnameinself.__dict__.keys():#判断属性是否存在raiseself.ConstError("can'tbindconst")ifnotname.isupper():raiseself.UpperCaseError("the'%s'isnotalluppercase"%name)self.__dict__[name]=valueimportsyssys.moduels[__name__]=_const()#将类生成的实例绑定到模块名const直接使用const来操作常量#文件名const.py测试importconstconst.V=7const.test=10#此处报绑定大小写错误print(const.V)const.V=5#此处会报错print(const.V)使用列表和数组列表(List)定义B=[]B.append([2,3,3])B.append([4,45,67])print(B)print(B[1][2])[[2,3,3],[4,45,67]]67数组np.array定义np.array是不能使用append的A=np.zeros((2,3))print(A)结果[[0.0.0.][0.0.0.]]List转np.arrayC=np.array(B)print(C)print(C[1,2])print(C[1][2])结果[[233][44567]]6767List或者np.array取值#List必须使用[i][j]这种形式print(B[1][2])#np.array可以使用[i][j]或者[i,j]两种形式print(C[1,2])print(C[1][2])#所以为避免胡乱,你可以都使用[i][j]这种形式命名规范下划线命名Python命名约定#单前导下划线:_var#告知其他程序员:以单个下划线开头的变量或方法仅供内部使用。#通配符从模块中导入Python不会导入带有前导下划线的名称def_internal_func():return42#############单末尾下划线:var_#单个末尾下划线(后缀)是一个约定,用来避免与Python关键字产生命名冲突。PEP8解释了这个约定。defmake_object(name,class_):...pass#############双前导下划线:__var#双下划线前缀会导致Python解释器重写属性名称,以避免子类中的命名冲突,防止变量在子类中被重写。#这也叫做名称修饰(namemangling)-解释器更改变量的名称,以便在类被扩展的时候不容易产生冲突。#############双前导和末尾下划线:__var__#由双下划线前缀和后缀包围的变量不会被Python解释器修改:#Python保留了有双前导和双末尾下划线的名称,用于特殊用途。例子有,__init__对象构造函数,或__call__---它使得一个对象可以被调用。#这些dunder方法通常被称为神奇方法最好避免在自己的程序中使用以双下划线(“dunders”)开头和结尾的名称,以避免与将来Python语言的变化产生冲突。classPrefixPostfixTest:def__init__(self):self.__bam__=42#############单下划线:_#单个独立下划线是用作一个名字,来表示某个变量是临时的或无关紧要的def_add(a,b):_=a+breturn_###########数据类型数据类型数据类型可以分为数字型和非数字型数字型整型(int)长度32位可以作为Long类型使用可以使用八进制、十六进制、二进制a=1int("3")#转成int类型参数为字符报错只保留整数,不进位id(-1)#查看内存地址浮点型(float)a=1.121212float("3")#强转为浮点数复数复数由实数部分和虚数部分构成,用a+bj或complex(a,b)表示,复数的实数部a和虚数部b都是浮点数complex(x)#x转换为复数,实数部分为x,虚数部分为0complex(x,y)#x,y转换为复数,实数部分为x,虚数部分为y数学计算importmathmath.ceil(x)#返回数字的上入整数ceil(4.1)=4math.floor()#返回数字的下舍整数floor(4.9)=4math.round(x[,n])#返回浮点数x的四舍五入值,n表示保留位数math.hypot(x,y)#返回欧几里得范数sprt(xx+yy)math.abs()...非数字型布尔(boolean)大小写注意1>=True0==Falsea=Trueb=Falsenota#Falsebool(a)#True判断真假bool(None)#FalseNone不是booleanBytes```字符串(string)字符串需要用单引号’’或双引号""括起来,是一种特殊的元组。不能改变字符串中的某个元素的值基础操作:索引、切片、乘法-多次输出、成员资格检查、长度len()、最大值、最小值str='Hello'print(str[0])#H#长度len(str)#查找内容findprint(str_.find('l'))#2#判断startswith,endswithprint(str_.startswith('H'))#Trueprint(str_.endswith('H'))#False#计算count在[start,end)之间sub出现的次数print(str_.count('l',0,3))#1#替换replaceprint(str_.replace('o','4'))#Hell4#切割splitprint(str_.split('e'))#['H','llo']print(str_.split('l'))#['He','','o']#修改大小写upperlowerprint(str_.upper())#HELLOprint(str_.lower())#hello#空格处理stripstr_="Helloworld"print(str_)#Helloworldprint(str_.strip())#Helloworldprint(str_.strip('Hello'))#world#字符串拼接joinstr_=','print(str_.join(['a','b','c']))#a,b,cstr_=''print(str_.join(['a','b','c']))##abc字典(dictionary)字典的每个元素是键值对,无序的对象集合,是可变容器模型,且可存储任意类型对象字典可以通过键来引用,键必须是唯一的且键名必须是不可改变的(即键名必须为Number、String、元组三种类型的某一种),但值则不必字典是使用{}大括号包含键值对dict={'name':'steve','age':18}print(dict)dict['name']#'steve'根据键名访问不存在报错dict.get('name')#通过get()访问值不存在返回Nonedict.pop('name')#获取指定key对应的value,并删除这个key-value对。dict['name']='aa'#修改dict.update({'name':'tom'})#修改,若键不存在,则添加deldict['name']#删除dict.clear()#清空字典print('name'indict)#判断键名是否存在###man={'name':'james','age':12}#获取所有键值对print(man.items())#结果为:dict_items([('name','tom'),('age',12),('sex','man')])#获取所有d键print(man.keys())#结果为dict_keys(['name','age','sex'])#获取所有值print(man.values())#结果为dict_values(['tom',12,'man'])####当程序要获取的key在字典中不存在时,该方法会先为这个不存在的key设置一个默认的value,然后再返回该key对应的valuecars={'BMW':8.5,'BENS':8.3,'AUDI':7.9}#设置默认值,该key在dict中不存在,新增key-value对print(cars.setdefault('PORSCHE',9.2))#9.2print(cars)#设置默认值,该key在dict中存在,不会修改dict内容print(cars.setdefault('BMW',3.4))#8.5print(cars)####使用给定的多个key(可以为列表、元组)创建字典,这些key对应的value默认都是None;也可以额外传入一个参数作为默认的value#使用列表创建包含2个key的字典a_dict=dict.fromkeys(['a','b'])print(a_dict)#{'a':None,'b':None}#使用元组创建包含2个key的字典b_dict=dict.fromkeys((13,17))print(b_dict)#{13:None,17:None}#使用元组创建包含2个key的字典,指定默认的valuec_dict=dict.fromkeys((13,17),'good')print(c_dict)#{13:'good',17:'good'}元组(tuple)tuple是使用()小括号包含各个数据项,可以在元组中放入另一个元素tuple与list的唯一区别是tuple的元素是不能修改,而list的元素可以修改tuple1=(True,1,'Hello')#创建一个元组print(tuple1)#(True,1,'Hello')tuple=(1,'2',(3,))tuple2=(1,)#创建单元素元组时,不能省略,tuple1[0]#获取元素tuple1[::-1]#元组反转#元组重复操作与列表类似#添加元组tuple1+=(4,)#末尾添加tuple1=tuple1[:2]+(3,)+tuple[2:]#指定位置添加#删除元组tuple1=tuple1[:2]+tuple1[3:]#通过拼接进行删除deltuple1#删除元组tuple1.count(5)#元素出现次数tuple1.index('True')#元素第一次c列表有序的可重复元素集合可以嵌套、迭代、修改、分片、追加、删除、成员判断列表是一个可变成都的顺序存储结构,每个位置存放的都是对象的指针类似于List集合#创建列表,,不同数据项用逗号隔开list=[1,'2',3.12]#访问数据list[0]#1len(list)#列表长度#修改元素list[1]=2#删除元素可以使用del语句或者remove(),pop()删除指定元素删除后索引自动更新dellist[0]#根据下标删除list.pop()#删除列表最后一个元素list.remove(3)#根据元素值删除列表中数据#列表拼接重复值不排除list+[1,2]#最值max(list)min(list)#序列转换为列表list(seq)#列表反转list[::-1]#返回反转后结果list.reverse()#将反转结果更新列表list.append('d')#追加list.insert(1,'d')#指定位置追加list.extend([1,2,3])#列表拼接str_=''.join(list)#列表转str集合(set)set是一个无序不重复元素的序列使用大括号{}或者set()函数创建集合操作:用set()创建一个空集合、使用set可以去重set1={'me','you','she','me'}print(set1)#{'me','she','you'}set1.add('22')#添加set1.update([10,37,42])#在s中添加多项set1.remove('H')#删除一项len(set1)#set长度set1.pop()#删除,并返回第一个值切片也叫截取,指对序列进行截取,选取序列中的某一段;语法:list[start:end]start起始索引,省略表示从0开始,end结束索引,省略表示直到列表结束;区间包含start不包含endlist=[1,2,3,4]list[1:3]#[2,3]list[:]#[1,2,3,4]list[:2]#[1,2]list[1:2:3]#[2]None空值算术运算符运算与java基本一致加1+2#3减2-1#1乘2*4#82**4#x的y次幂16除#结果为浮点数9/3#3.0#只取结果整数部分小数部分抛弃10//3#3#余数计算10%3#1#同时得到商和余数divmod(10,3)#(3,1)赋值运算c=a+b#赋值c+=ac-=ac*=ac/=a#等价c=c/ac%=ac**=ac//=a#c=c//a逻辑运算a=10;b=20(aandb)#20(aandb)a为True返回b;a为False或0返回a(aorb)#10(xory)a不等于0或为True返回a;a等于0或Fasle返回ynot(aandb)#False取反返回True或False成员运算符用于判断对象是否在某个集合中返回True或Falseainlist#如果a在y中返回Trueanotinlist#a不在y中返回True身份运算符用于判断是否引用自同一个对象aisb#如果a与b都引用自同一个对象返回True基本类型大多数值相同对象相同aisnotb#相反值三目运算a=1b=2h=""h=a-bifa>belsea+b#如果a>b返回True执行a-b,否则执行a+b方法基本结构:def<方法名>(<...参数>):passretrun<value>#调用方法<方法名>(<...参数>)主方法:定义的方法应在主方法之前if__name__=='__main__':print("thisismainfunction")参数deftest2_1(a,b):print('test2_1',a)returna+b#实参deftest2_2(a,b):#形参a+=2print('test2_2',a)#形参returntest2_1(a,b)#实参特殊参数#args为元组deffunc_1(self,*args,flag='flag'):print(self)print(args)print(flag)print(type(args))#args为字典后面不可加参数deffunc_2(self,**args):print(self)print(args.get('test'))print(type(args))#合用,表输入任意参数deffunc_3(*args,**kwargs):print(args)print(kwargs)if__name__=='__main__':func_1("abc",1,2,3,flag='thisflag')print('-'*10)func_2("abc",name='aa',test='test')print('-'*10)func_3(1,2,3,4,arr='args',name='test')print('-'*10)func_3()for循环#for<item>in<可迭代变量>:#passforiin[1,2,3,4]print(i)#for循环嵌套foriin[1,2,3]:fornin[2,3,4]:passpassIf判断#if<boolean表达式>:#pass#elif<boolean表达式>:#pass#else:#passWhile循环while<boolean表达式>:passzrange()创建一个整数列表,一般用在for循环中。#循环输出0-10foriinrange(10):print(i)#循环输出2-10foriinrange(2,10):print(i)递归#递归函数defrecursion_test(num):ifnum==0:return0elifnum>=997:print("最大值不超过1000")exit()returnnum+recursion_test(num-1)匿名函数lambda:int(string)+10#实例deflambda_test(string):returnlambda:int(string)+10#参数func默认值为None,调用时可省略不写deflambda_test2(a,b,func=None):iffuncisNone:returna+breturnfunc(a,b)语法糖#语法糖list1=[xforxinrange(10)ifx%2!=0]list2={x:str(x+1)forxinrange(10)ifx%2!=0}list3={xforxinrange(10)ifx%2!=0}list4=[lambdax:x+iforiinrange(10)]print(list4[0](10))生成器#yield标志该方法为生成器defcreateNum():a,b=0,1forcinrange(10):yieldba,b=b,a+b#使用s1=createNum()s2=createNum()whileTrue:print(next(s1))#调用方式一print(s1.__next__())#调用方式二装饰器#内部验证defw1(func):definners():print("check...")func()returninners@w1#装饰器在程序一开始即执行deftest_1():print("test")#调用if__name__=='__main__':test_1()##########异常处理"""try:passexcept:pass"""try:print(1/0)exceptExceptionase:print(e)"""except:#捕获所有异常except:<异常名>:#捕获指定异常except:<异常名1,异常名2):捕获异常1或者异常2except:<异常名>,<数据>:捕获指定异常及其附加的数据except:<异常名1,异常名2>:<数据>:捕获异常名1或者异常名2,及附加的数据库""""""AttributeError调用不存在的方法引发的异常EOFError遇到文件末尾引发的异常ImportError导入模块出错引发的异常IndexError列表越界引发的异常IOErrorI/O操作引发的异常,如打开文件出错等KeyError使用字典中不存在的关键字引发的异常NameError使用不存在的变量名引发的异常TabError语句块缩进不正确引发的异常ValueError搜索列表中不存在的值引发的异常ZeroDivisionError除数为零引发的异常"""断言#语法格式expressionassert表达式"""assert语句用来声明某个条件是真的。如果你非常确信某个你使用的列表中至少有一个元素,而你想要检验这一点,并且在它非真的时候引发一个错误,那么assert语句是应用在这种情形下的理想语句。当assert语句失败的时候,会引发一AssertionError。"""assertexpression[,arguments]assert表达式[,参数]#自定义异常classShortInputException(Exception):'''自定义的异常类'''def__init__(self,length,atleast):#super().__init__()self.length=lengthself.atleast=atleastdefmain():try:s=input('请输入-->')iflen(s)<3:#raise引发一个你定义的异常raiseShortInputException(len(s),3)exceptShortInputExceptionasresult:#x这个变量被绑定到了错误的实例print('ShortInputException:输入的长度是%d,长度至少应是%d'%(result.length,result.atleast))else:print('没有异常发生.')main()文件#open(<绝对路径>,<访问模式>)#写文件#fp=open('text.text','w')#文件流写模式#fp.write([1,2,3])#fp.close()#关闭文件流#读文件#fp=open('text.text','r')#文件流读模式#context=fp.readlines()#读取所有行,输出列表#context=fp.read(<n>)#读取一行,默认0#print(context)#fp.close()#关闭文件流#序列化importjson#fp=open('text.text','w')#tem=[1,2,3,4]#json.dump(tem,fp)#序列化#fp.close()#关闭文件流#反序列化#捕获异常try:fp=open('text.text','r')res=json.load(fp)print(res)print(type(res))fp.close()exceptFileNotFoundErrorase:print("error")#自动关闭流操作withopen('text.text','r')asfp:print(fp.readlines())访问模式访问模式说明r以只读方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,则报错。这是默认模式。w打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。a打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。r+打开一个文件用于读写。文件指针将会放在文件的开头。w+打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。a+打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。rb以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。wb以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。ab以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说.新的内容将会被写入到R有内容之后。如果该文件不存在.创建新文件讲行写入.网络基本概念概述Https协议:HTTP+SSL(安全套间层)互联网上使用的HTTP协议是明文的,存在很多缺点——比如传输内容会被偷窥(嗅探)和算改。发明SSL协议,就是为了解决这些问题。作用:1.验证服务器是不是我们想要访问的服务界2.数据传输过程中,进行数据加密爬虫时需要关注点;ssl验证设置为:verify=FalseURL形式URL的形式:scheme://host[:port#]/path/.../[?query-string][#anchor]scheme:协议(例收:http、https、ftp)host:服务器的IP地址或域名path:访问资源的路径query-string:参数,发送给http服务器的数据anchor:锚(跳转到网页的指定锚点位置)e.g:http://localhost:4000/file/part01/1.2.htmlhttp://item.jd.com/11936238.html#product-detail常见请求方式GET数据请求POST表单提交,长数据获取相应状态码1xx:指示信息--表示请求已接收,继续处理2xx:成功------表示请求已被成功接收、理解、接受3xx:重定向----要完成请求必须进行更进一步的操作4xx:客户端错误--请求有语法错误或请求无法实现5xx:服务器端错误--服务器未能实现合法的请求#常见状态代码、状态描述、说明:2e0oK#客户端请求成功200OK#客户端请求成功302redirect#重定向400BadRequest#客户端请求有语法错误,不能被服务器所理解401Unauthorized#请求未经授权,这个状态代码必须和wwl-Authenticate报头域一起使用484NotFound#请求资源不存在,eg:输入了错误的URL500InternalServerError#服务器发生不可预期的错误503ServerUnavailable#服务器当前不能处理客户端的请求,一段时间后可能恢复正常服务器返回给浏览器的格式responseHTTP/1.1288oKBdpagetype:2Bdqid:exf73ec47900013621Cache-Control:privateConnection:Keep-AliveContent-Encoding:gzipContent-Type:text/html;charset-utf-8Date:Sun,18Nov201808:37:32GMTExpires:Sun,18Nov201888:37:32GMTServer:BWS/1.1Set-Cookie:BDSVRTN-251;path=/Set-Cookie:BD_HOME-1;path=/Set-Cookie:H_PS_PSSID=1445_21097_27400_27508;path=/;domain=.baidu.comStrict-Transport-Security:max-age-172888X-Ua-Compatible:IE=Edge,chrome=1Transfer-Encoding:chunked爬虫概念概述目标:抓取网站中需要的数据核心:爬取网页:爬取整个网页,包含网页中所有的内容解析数据:将网页中得到的数据进行解析难点:爬虫与反爬虫之间博弈用途:数据分析、人工数据集社交软件冷启动舆情监控竞争对手监控相关库:requests:发送网络请求,返回响应数据requests的底层实现就是urllibrequests在Python2和Python3通用,方法完全一样requests简单易用requests能够自动帮助我们解压(gzip压缩的)网页内容Robots协议一个约定成俗的协议,指明robots.txt文件指明爬虫可以爬取的网页权限,说明本网站哪些内容不可以被抓取。起不到简直作用一般只有大型搜索引擎才会遵守。爬虫类型通用爬虫功能:访问网页->抓取数据->数据存储->数据处理->提供检索服务网站排名(SEO):根据pagerank算法值进行排名(参考网站流量、点击率等)竞价排名缺点:抓取的数据大多是无用的不能根据用户的需求来精确获取数据聚焦爬虫功能:针对特定网站的爬虫,根据需求实现爬虫程序抓取需要的数据设计思路:确定要爬取的url模拟浏览器通过http协议访问,,获取html代码解析html字符串(根据一定规则提取需要的数据)反爬虫手段User-Agent:用户代理,简称UA。是一个特殊字符串头,使得服务器能识别客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等代理IP透明代理:对方服务器可以知道你使用代理,且知道你的真实IP匿名代理:对方服务器可以知道你使用代理,但不知道你的真实IP高匿代理:对方服务器不知道你使用代理,且不知道你的真实IP验证码访问打码平台:云打码平台动态加载网页网站返回js数据,并不是网页的真实数据selenium驱动真实浏览器发送请求数据加密分析js代码urllib库urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了urllib。urllib中一共有四个模块,分别如下:urllib.request:用于打开和阅读URLurllib.error:包含由引发的异常urllib.requesturllib.parse:用于解析URLurllib.robotparser:用于解析robot.txt文件实例importurllib.requesturl='http://www.baidu.com'response=urllib.request.urlopen(url)context=response.read().decode('utf-8')#withopen('baidu.html','w',encoding='utf-8')asfp:#fp.write(context)#response.readline()#读取一行#response.readlines()#按行读取print(response.getcode())#响应码#print(response.headers)#请求头#print(response.getheaders())#响应头#print(response.geturl())#请求地址下载url_page='http://www.baidu.com'#response=urllib.request.urlretrieve(url_page,'baidu.html')urllib.request.urlretrieve('https://img-home.csdnimg.cn/images/20210917084230.jpg','test.png')包装请求对象header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}url='https://www.baidu.com'request=urllib.request.Request(url,headers=header)response=urllib.request.urlopen(request)context=response.read().decode('utf-8')print(context)编解码header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}url='https://www.sogou.com/web?'#print(parse.quote('测试'))#编码data={'ie':'UTF-8','query':'测试'}#print(url+parse.urlencode(data))#参数编码url=url+parse.urlencode(data)request=urllib.request.Request(url,headers=header)response=urllib.request.urlopen(request)context=response.read().decode('utf-8')print(context)POST请求importurllib.parseimporturllib.requestimportjson#post请求url='https://fanyi.baidu.com/sug'header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}data={'kw':'spider'}data=urllib.parse.urlencode(data).encode('utf-8')#post参数传入请求对象中request=urllib.request.Request(url,data,header)response=urllib.request.urlopen(request)context=response.read().decode('utf-8')print(json.loads(context))代理代理IP:http://www.66ip.cn/nm.html使用handler、opener对象请求url='http://www.baidu.com'header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}request=urllib.request.Request(url,headers=header)handler=urllib.request.HTTPHandler()#获取handler对象opener=urllib.request.build_opener(handler)#获取opener对象response=opener.open(request)#调用opener对象获取responsecontext=response.read().decode('utf-8')withopen('baidu.html','w',encoding='utf-8')asfp:fp.write(context)代理服务器1.代理的常用功能?1.突破自身IP访问限制,访问国外站点。2.访问一些单位或团体内部资源扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。3.提高访问速度扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度。4.隐藏真实IP扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。2.代码配置代理创建Reuqest对象创建ProxyHandler对象用handler对象创建opener对象使用opener.open函数发送请求importrandomimporturllib.requesturl='http://www.baidu.com'header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}#代理池proxies_pool=[{'http':'121.230.210.168:3256'},{'http':'211.65.197.93:80'},{'http':'114.230.107.75:3256'},{'http':'117.88.246.178:3000'},]#随机选择一个其中一条代理IPproxies=random.choice(proxies_pool)request=urllib.request.Request(url,headers=header)handler=urllib.request.ProxyHandler(proxies=proxies)#获取handler对象opener=urllib.request.build_opener(handler)#获取opener对象response=opener.open(request)#调用opener对象获取response解析常用工具xpathimportrandomimporturllib.requestfromlxmlimportetreeurl='http://www.baidu.com'header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}request=urllib.request.Request(url,headers=header)handler=urllib.request.HTTPHandler()#获取handler对象opener=urllib.request.build_opener(handler)#获取opener对象response=opener.open(request)#调用opener对象获取responsehtml_tree=etree.HTML(response.read().decode('utf-8'))#网页数据data=html_tree.xpath('//img[@id="s_lg_img"]/@src')#选择性解析的列表img_url="https:"+data[0]#图像地址urllib.request.urlretrieve(img_url,'baidu.png')#下载图像JsonPath参考博客:https://blog.csdn.net/luxideyao/article/details/77802389BeautifulSoup"""简称:bs4优点:接口设计人性化,使用方便缺点:效率没有lxml效率高"""frombs4importBeautifulSoupsoup=BeautifulSoup(open('baidu.html',encoding='utf-8'),'lxml')print(soup.title.text)#获取标签属性print(soup.title)#获取标签bs4的方法使用soup=BeautifulSoup(open('baidu.html',encoding='utf-8'),'lxml')#print(soup.title.text)#find()find_all()##########print(soup.find('a'))#返回第一个a标签#print(soup.find('a',title='a'))#返回第一个title值为‘a’的a标签,#print(soup.find_all('input'))#查询所有input#print(soup.find_all('input',limit=2))#查询前两个input#print(soup.find_all(['input','img']))#查询多个#select()####################select()返回列表,查询多个数据#.<>代表class->类选择器##<>代表id->id选择器#print(soup.select('#c-tips-container'))#print(soup.select('.wrapper_new'))#print(soup.select('li[id]'))#查询li标签中有id的标签#print(soup.select('li[id="l2"]'))#查询li标签中id为l2的标签#print(soup.select('divli'))#div下的li#print(soup.select('div>ul>li'))#某标签下的第一级子标签#print(soup.select('a,div'))#查询多个#获取节点信息#################content=soup.select("meta[name='description']")[0]#print(content.string)#如果标签对象中除了内容还有标签,那string就获取不到数据,而get_text()可以获取数据print(content.get_text())#获取标签内容#获取标签属性三种方式print(content.attrs.get('content'))#推荐使用print(content.attrs.get('content'))print(content['content'])Selenium概述Selenium是一个web应用程序测试工具测试直接运行在浏览器中,就像真正用户操作支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试支持无界面浏览器操作作用:模拟浏览器功能,自动执行网页中的js代码,实现动态加载chrome浏览器驱动:http://chromedriver.storage.googleapis.com/index.html驱动与版本映射表:http://blog.csdn.net/huilan_same/article/details/51896678使用基本使用fromseleniumimportwebdriver#操作浏览器驱动对象driver_path='chromedriver.exe'browser=webdriver.Chrome(driver_path)#访问网址url='http://www.baidu.com'browser.get(url)#获取网页源码content=browser.page_sourceprint(content)元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,webDriver提供很多定位元素的方法importtimefromseleniumimportwebdriver#操作浏览器驱动对象driver_path='chromedriver.exe'browser=webdriver.Chrome(driver_path)#访问网址################url='https://www.baidu.com'browser.get(url)#获取网页源码#content=browser.page_source#print(content)#定位元素#################eg_btn=browser.find_element_by_id('su')#eg_btn=browser.find_element_by_name('wd')#eg_btn=browser.find_element_by_xpath('//input[@id="su"]')#eg_btn=browser.find_element_by_tag_name('input')#eg_btn=browser.find_element_by_css_selector('#kw')[0]#eg_btn=browser.find_element_by_link_text('新闻')input_=browser.find_element_by_id('kw')#获取元素信息##############tag_name:标签名#text:元素文本#get_attribute(<>)元素属性#print(eg_btn.get_attribute('class'),eg_btn.text,eg_btn.tag_name,sep=',')#s_ipt,,input#元素交互##################输入input_.send_keys('周杰伦')#点击#获取点击按钮btn_=browser.find_element_by_id('su')btn_.click()time.sleep(2)#模拟js滚动js_roll='document.documentElement.scrollTop=100000'browser.execute_script(js_roll)time.sleep(2)#获取下一页按钮btn_next=browser.find_element_by_xpath('//a[@class="n"]')btn_next.click()time.sleep(2)#后退操作browser.back()time.sleep(2)#前进操作browser.forward()time.sleep(2)browser.save_screenshot('bai.png')#保存屏幕快照#退出browser.quit()无界面浏览器:Phantomjs:phantomjs.exe支持页面元素查找,js执行不进行CSS和GUI渲染,效率比真实浏览器较高Chromehandless:Chrome-headless模式,Google针对Chrome浏览器59版新增加的一种模式,可以让你不打开UI界面的情况下使用Chrome浏览器,所以运行效果与Chrome保持完美一致。系统要求win:chrome>=60Unix/Linux:chrome>=59python3.6+selenium.4.*chromeDriver==2.31defshare_browser():chrome_options=Options()chrome_options.add_argument('--headless')chrome_options.add_argument('--disable-gpu')#chrome浏览器文件路径:chrome.exepath=r'C:\ProgramFiles\Google\Chrome\Application\chrome.exe'chrome_options.binary_location=pathreturnwebdriver.Chrome(options=chrome_options)url='https://www.baidu.com'browser=share_browser()browser.get(url)browser.save_screenshot('save.png')request库概述参考文档:https://cn.python-requests.org/zh_CN/latest/Requests唯一的一个非转基因的PythonHTTP库,人类可以安全享用。Requests完全满足今日web的需求。Keep-Alive&连接池国际化域名和URL带持久Cookie的会话浏览器式的SSL认证自动内容解码基本/摘要式的身份认证优雅的key/valueCookie自动解压Unicode响应体HTTP(S)代理支持文件分块上传流下载连接超时分块请求支持.netrc使用基本封装importrequestsclassrequestDemo:def__init__(self,url):self._url=urldefrun(self):header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}response=requests.get(self._url,headers=header)print(response.status_code)response.encoding='utf-8'#response.url#返回url#response.status_code#返回状态码#response.headers#返回响应头#response.content#返回二进制源码数据returnresponse.text#返回源码@propertydefurl(self):returnself._urlif__name__=='__main__':request_demo=requestDemo('http://www.baidu.com')#withopen('text.html','w')asf:#f.write(requestDemo.run())text=request_demo.run()withopen('text.html','w')asf:f.write(text)代理importrequests#请求头header={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}#请求路径url="https://t7.baidu.com/it/u=1878516430,"\"2044457199&fm=218&app=92&f=JPEG?w=121&h=75&s=918398561EC1284D18B2BC5B03004099"url2='http://www.baidu.com/s'#请求参数params={'wd':'python'}#请求代理proxies={'http':'http://118.117.189.75:3256'}response=requests.get(url2,headers=header,params=params,proxies=proxies)print(response)#response.encoding='utf-8'#print(response.text)print(response.status_code)#输出到本地#withopen('logo.png','wb')asf:#f.write(response.content)get/post请求"""get和post区别?1:get请求的参数名字是paramspost请求的参数的名字是data2:请求资源路径后面可以不加?3:不需要手动编解码4:不需要做请求对象的定制"""#get请求importrequestsheader={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}url='https://www.baidu.com/s'data={'wd':'北京'}response=requests.get(headers=header,params=data,url=url)print(response.text)#post请求importjsonimportrequestsheader={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)''Chrome/93.0.4577.63Safari/537.36Edg/93.0.961.47'}url='https://fanyi.baidu.com/sug'data={'kw':'eye'}response=requests.post(headers=header,data=data,url=url)content=response.textobj=json.loads(content)print(obj)验证码破解:超级鹰打码平台Scrapy概述scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。安装:pipinstalscrapy安装时常出现错误的原因可能是因为没安装依赖库:twisted手动安装:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted报错:win32错误解决:pipinstallpypiwin32Anaconda1、anaconda是一个python的发行版,包括了python和很多常见的软件库,和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易。2、Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项在安装完成之后会多几个应用AnacondaNavigtor:用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在Navigator中手工实现。Jupyternotebook:基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程。qtconsole:一个可执行IPython的仿终端图形界面程序,相比PythonShell界面,qtconsole可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。spyder:一个使用Python语言、跨平台的、科学运算集成开发环境。Scrapy创建项目终端输入:scrapystartproject<项目名>cd/dF:\learning\Python\pythonProjectscrapystartprojectdemo4项目组成spiders#存储爬虫文件__init__.py<自定义爬虫文件>.py#自己创建实现爬虫核心功能的核心__init__.pyitems.py#定义爬取的数据结构middlewares.py#中间件代理pipelines.py#管道文件,只有一个类用于处理下载数据后续处理,默认300优先级,《值越小优先级越高(1-1000)》settings.py#配置文件e.g:是否遵循robots协议、User-Agent定义等创建按爬虫文件cd/dF:\learning\Python\pythonProject\demo4\spidersscrapygenspider<爬虫名字><网页域名>爬虫文件基本组成继承scrapy.Spider类name='baidu'#运行爬虫文件时使用的名字allowed_domains#爬虫允许的域名,在爬取时不是在该域名下的url会自动过滤start_urls#声明爬虫的其实地址,可以写多个url,一般一个defparse(self,response)#解析数据的回调函数response.text#字符串response.body#二进制文件response.xpath()#selector列表extract()#提取的selector对象的data属性值extract_first()#提取的是selector列表的第一个数据运行爬虫代码scrapycrawl<爬虫名字>Scrapy架构组成引擎自动运行,无需关注,会自动组织所有的请求对象,分发给下载器下载器从引擎处获取到请求对象后,请求数据spidersspider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说,spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。调度器有自己的调度规则,无需关注管道(Itempipeline)最终处理数据的管道,会预留接口供我们处理数据当Item在spider中被收集之后,它将会被传递到ItemPipeline,一些组件会按照一定的顺序执行对Item的处理。每个itempipeline组件(有时称之为“ItemPipeline")是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。以下是itempipeline的一些典型应用:清理HTMAL数据验证爬取的数据(检查item包含某些字段)查重(并丢弃)将爬取结果保存到数据库中工作原理:ScrapyShellscrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。该终端是用来测试xpath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。一旦熟悉了scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。安装:pipinstallipython如果您安装了IPython,Scrapy终端将使用IPython(替代标准Python终端)。IPython终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。终端操作scrapyshellwww.baidu.comresponse.xpath('//input[@id="su"]/@value').extract_first()#'百度一下'使用爬虫文件importscrapyfromdemo4.itemsimportDemo4ItemclassDangSpider(scrapy.Spider):name='dang'allowed_domains=['http://category.dangdang.com/cp01.05.06.00.00.00.html']start_urls=['http://category.dangdang.com/cp01.05.06.00.00.00.html']defparse(self,response):li_list=response.xpath('//ul[@id="component_59"]/li')forliinli_list:alt=li.xpath('.//img/@alt').extract_first()img_src=li.xpath('.//img/@data-original').extract_first()ifnotimg_src:img_src=li.xpath('.//img/@src').extract_first()img='http:'+img_srcprice=li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()#构建要给item#递交pipelinesyieldDemo4Item(name=alt,img=img,price=price)setting文件中开启管道pipelines#Defineyouritempipelineshere##Don'tforgettoaddyourpipelinetotheITEM_PIPELINESsetting#See:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#usefulforhandlingdifferentitemtypeswithasingleinterface#若需要使用管道,需要手动在配置中开启classDemo4Pipeline:#爬虫文件开始前执行的方法defopen_spider(self):pass#item:yield传递的对象defprocess_item(self,item,spider):withopen('books.json','a+',encoding='utf-8')asfp:fp.write(str(item).replace("'",'"'))returnitem#爬虫文件执行完后,执行的方法defclose_spider(self):pass输出标准json数据fromscrapy.exportersimportJsonItemExporterclassDemo4Pipeline:#构造方法def__init__(self):#self.json_file=open('data.json','w+',encoding='UTF-8')self.json_file=open('data.json','wb')#构建JsonLinesItemExporter对象,设定不使用ASCII编码,并指定编码格式为'UTF-8'self.json_exporter=JsonItemExporter(self.json_file,ensure_ascii=False,encoding='UTF-8')#声明exporting过程开始,这一句也可以放在open_spider()方法中执行。self.json_exporter.start_exporting()#爬虫文件开始前执行的方法defopen_spider(self,spider):#self.json_file.write('[\n')pass#item:yield传递的对象defprocess_item(self,item,spider):#withopen('book.json','a+',encoding='utf-8')asfp:#fp.write(str(item).replace("'",'"'))#item_json=json.dumps(dict(item),ensure_ascii=False)#self.json_file.write('\t'+item_json+',\n')self.json_exporter.export_item(item)returnitem#爬虫文件执行完后,执行的方法defclose_spider(self,spider):#self.json_file.write('\n]')##关闭文件#self.json_file.close()#**************#声明exporting过程结束,结束后,JsonItemExporter会将收集存放在内存中的所有数据统一写入文件中self.json_exporter.finish_exporting()#关闭文件self.json_file.close()进行多页查询allowed_domains=['category.dangdang.com']start_urls=['http://category.dangdang.com/cp01.05.06.00.00.00.html']base_url='http://category.dangdang.com/pg'page=1defparse(self,response):li_list=response.xpath('//ul[@id="component_59"]/li')forliinli_list:alt=li.xpath('.//img/@alt').extract_first()img_src=li.xpath('.//img/@data-original').extract_first()ifnotimg_src:img_src=li.xpath('.//img/@src').extract_first()img='http:'+img_srcprice=li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()#构建要给item#递交pipelinesyieldDemo4Item(name=alt,img=img,price=price)#多次重复请求ifself.page<100:self.page+=1url=self.base_url+str(self.page)+'-cp01.05.06.00.00.00.html'#Request()对象可以传入meta接收字典用于传递数据yieldscrapy.Request(url=url,callback=self.parse)CrawlSpider继承自scrapy.spiderCrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定链接,然后再想这些链接发送请求就是说如果爬取王爷后,需要提取链接并再次爬取,可以使用CrawlSpider提取链接方式#使用链接提取器"""scrapy.linkextractors.LinkExtractor(allow=<>,#正则表达式提取符合正则的链接deny=<>,#(不用)正则表达式不提取符合正则的链接allow_domains=<>,#(不用)允许的域名deny_domains=<>,#(不用)不允许的域名restrict_xpaths=<>,#xpath,提取符合xpath规则的链接restrict_css=<>#提取符合选择器规则的链接)"""#提取链接link1=LinkExtractors(allow='list_123_\d+\.html')#正则用法url=link1.extract_links(response)创建爬虫文件scrapygenspider-tcrawl<name><url>使用fromscrapy.linkextractorsimportLinkExtractorfromscrapy.spidersimportCrawlSpider,Rulefromdemo5.itemsimportDemo5ItemclassReadSpider(CrawlSpider):name='read'allowed_domains=['www.dushu.com']start_urls=['http://www.dushu.com/book/1617_1.html']rules=(Rule(LinkExtractor(allow=r'/book/1617_\d+.html'),callback='parse_item',follow=False),)defparse_item(self,response):img_list=response.xpath('//div[@class="bookslist"]//img')foriteminimg_list:name=item.xpath('./@alt').extract_first()src=item.xpath('./@data-original').extract_first()yieldDemo5Item(name=name,src=src)爬取数据并写入数据库pymysql库爬取读书网fromscrapy.linkextractorsimportLinkExtractorfromscrapy.spidersimportCrawlSpider,Rulefromdemo5.itemsimportDemo5ItemclassReadSpider(CrawlSpider):name='read'allowed_domains=['www.dushu.com']start_urls=['http://www.dushu.com/book/1617_1.html']rules=(#follow为True是否跟进表示一直爬取知道爬取结束,按照提取链接规则进行提取Rule(LinkExtractor(allow=r'/book/1617_\d+.html'),callback='parse_item',follow=True),)defparse_item(self,response):img_list=response.xpath('//div[@class="bookslist"]//img')foriteminimg_list:name=item.xpath('./@alt').extract_first()src=item.xpath('./@data-original').extract_first()yieldDemo5Item(name=name,src=src)声明属性importscrapyclassDemo5Item(scrapy.Item):#definethefieldsforyouritemherelike:#name=scrapy.Field()name=scrapy.Field()src=scrapy.Field()通道中定义动作importpymysqlfromscrapy.utils.projectimportget_project_settings#打印数据classDemo5Pipeline:defprocess_item(self,item,spider):print('*'*10)print(str(item))print('*'*10)returnitem#第二通道上传数据classMysqlPipeline:defopen_spider(self,spider):settings=get_project_settings()#settings['DB_USER']self.host=settings['DB_HOST']self.port=settings['DB_PORT']self.user=settings['DB_USER']self.pwd=settings['DB_PWD']self.name=settings['DB_NAME']self.charset=settings['DB_CHARSET']self.conect()defconect(self):self.connect=pymysql.connect(host=self.host,port=self.port,user=self.user,password=self.pwd,db=self.name,charset=self.charset)self.cursor=self.connect.cursor()defprocess_item(self,item,spider):sql='insertintobook(name,src)values("{}","{}")'.format(item.get('name'),item.get('src'))self.cursor.execute(sql)#执行sql语句self.connect.commit()#提交事务returnitemdefclose_spider(self,spider):self.cursor.close()self.connect.close()在setting文件中配置数据库数据DB_HOST='127.0.0.1'DB_PORT=3306DB_USER='root'DB_PWD='123456'DB_NAME='subject'DB_CHARSET='utf8'#注册自定义通道ITEM_PIPELINES={'demo5.pipelines.Demo5Pipeline':300,'demo5.pipelines.MysqlPipeline':301,}日志处理日志级别'''等级从下往上逐级递增默认日志等级为DEBUGCRITCAL#严重错误ERROR#一般错误WARNING#警告INFO#一般信息DEBUG#调试信息settings.py添加属性指定日志级别LOG_FILE<输出文件名>将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.logLOG_LEVEL<日志等级>设置日志显示的等级,就是显示哪些,不显示哪些'''scrapy的post请求重写start_requests方法():defstart_requests(self)start_requests返回值#scrapy_FormRequest(url=url,headers=headers,callback=self.parse_item,formdata=data)#url要发送的post地址#headers可以定制头信息#callback回调函数#formdatapost所携带的数据(字典类型)实际使用importjsonimportscrapyclassFanyiSpider(scrapy.Spider):name='fanyi'allowed_domains=['https://fanyi.baidu.com/sug']#start_urls=['http://fanyi.baidu.com/']##defparse(self,response):#passdefstart_requests(self):url='https://fanyi.baidu.com/sug'data={'kw':'detail'}yieldscrapy.FormRequest(url=url,formdata=data,callback=self.parse_second)defparse_second(self,response):content=response.textprint(json.loads(content))scrapy代理参考1:https://www.pythontab.com/html/2014/pythonweb_0326/724.html参考2:https://blog.csdn.net/weixin_38819889/article/details/109018429?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163204694616780265464944%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163204694616780265464944&biz_id=0&spm=1018.2226.3001.4187方式一:直接在爬虫程序中设置proxy字段在自己具体的爬虫程序中设置proxy字段,代码如下,直接在构造Request里面加上meta字段即可classQuotesSpider(scrapy.Spider):name="quotes"defstart_requests(self):urls=['http://quotes.toscrape.com/page/1/','http://quotes.toscrape.com/page/2/',]forurlinurls:yieldscrapy.Request(url=url,callback=self.parse,meta={'proxy':'http://proxy.yourproxy:port'})#添加meta属性,并将代理IP加入proxydefparse(self,response):forquoteinresponse.css('div.quote'):yield{'text':quote.css('span.text::text').extract_first(),'author':quote.css('spansmall::text').extract_first(),'tags':quote.css('div.tagsa.tag::text').extract(),}方式二:使用中间件DownloaderMiddleware进行配置在settings.py文件中,找到DOWNLOADER_MIDDLEWARES它是专门用来用配置scrapy的中间件.我们可以在这里进行自己爬虫中间键的配置,配置后如下:DOWNLOADER_MIDDLEWARES={'WandoujiaCrawler.middlewares.ProxyMiddleware':100,}#其中WandoujiaCrawler是我们的项目名称,后面的数字代表中间件执行的优先级。#官方文档中默认proxy中间件的优先级编号是750,我们的中间件优先级要高于默认的proxy中间键。中间件middlewares.py的写法如下(scrapy默认会在这个文件中写好一个中间件的模板,不用管它写在后面即可):#-*-coding:utf-8-*-classProxyMiddleware(object):defprocess_request(self,request,spider):request.meta['proxy']="http://proxy.yourproxy:port""""1.是proxy一定是要写成http://前缀,否则会出现to_bytesmustreceiveaunicode,strorbytesobject,gotNoneType的错误.2.是官方文档中写到process_request方法一定要返回request对象,response对象或None的一种,但是其实写的时候不用return,乱写可能会报错。另外如果代理有用户名密码等就需要在后面再加上一些内容:"""如果代理有用户名密码等就需要在后面再加上一些内容:#Usethefollowinglinesifyourproxyrequiresauthenticationproxy_user_pass="USERNAME:PASSWORD"#setupbasicauthenticationfortheproxyencoded_user_pass=base64.encodestring(proxy_user_pass)request.headers['Proxy-Authorization']='Basic'+encoded_user_pass
