

概述
Python提供了高效的高级数据结构,还能简单有效地面向对象编程。是一种解释型脚本语言。其解释器易于扩展,可以使用C或C++扩展新的功能和数据类型,也可用于可定制化软件中的扩展程序语言。
Python的创始人为Guido van Rossum。Python的作者有意的设计限制性很强的语法,使得不好的编程习惯(例如if语句的下一行不向右缩进)都不能通过编译。其中很重要的一项就是Python的缩进规则。
Python的设计哲学是“优雅”、“明确”、“简单”。P ython本身被设计为可扩充的。并非所有的特性和功能都集成到语言核心。Python提供了丰富的API和工具,以便程序员能够轻松地使用C语言、C++、Cython来编写扩充模块。
Python在执行时,首先会将.py文件中的源代码编译成Python的byte code(字节码),然后再由Python Virtual Machine(Python虚拟机)来执行这些编译好的byte code。这种机制的基本思想跟Java,.NET是一致的。然而,Python Virtual Machine与Java或.NET的Virtual Machine不同的是,Python的Virtual Machine是一种更高级的Virtual Machine。这里的高级并不是通常意义上的高级,不是说Python的Virtual Machine比Java或.NET的功能更强大,而是说和Java 或.NET相比,Python的Virtual Machine距离真实机器的距离更远。或者可以这么说,Python的Virtual Machine是一种抽象层次更高的Virtual Machine。
基于C的Python编译出的字节码文件,通常是.pyc格式。
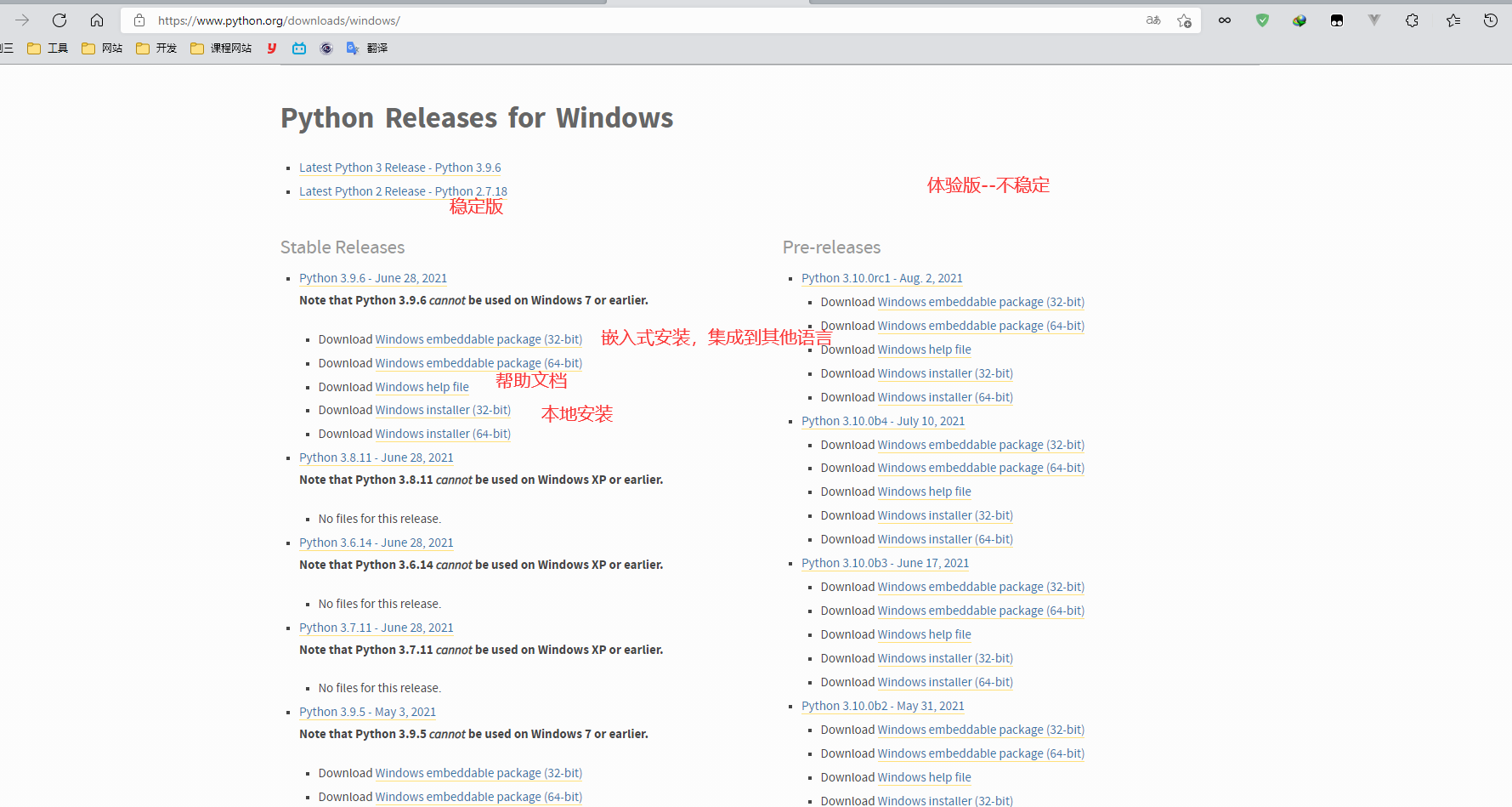
安装
官网网址: https://www.python.org/
安装时勾选 Add python 3.9 to PATH :添加环境变量,勾选时会自动添加环境变量,不够选,安装完成时需自己配置环境变量
命令行窗口python检查是否安装成功
pip
Python官方的PyPi仓库为我们提供了一个统一的代码托管仓库,所有的第三方库,甚至你自己写的开源模块,都可以发布到这里,让全世界的人分享下载。 python有两个著名的包管理工具easy_install和pip。在python 2中easy_install是默认安装的,而pip需要我们手动安装。随着Python版本的提高,easy_install旧经逐渐被淘汰,但是一些比较老的第三方库,在现在仍然只能通过easy _install进行安装。目前 ,pip已经成为主流的安装工具,自Python 2 >=2.7.9或者Python 3.4以后默认都安装有pip
在线安装第三方库
豆瓣镜像源:https://pypi.douban.com/simple
清华镜像源:https://pypi.tuna.tsinghua.edu.cn/simple
# 普通安装
pip install requests
# 指定版本安装
pip install robotframework==2.8.7
# 卸载已安装的库
pip uninstall requests
# 列出已安装库
pip list
# 批量安装
pip install -r F:\Desktop\install.txt
# 将已安装库列表保存到文本文件中
pip freeze > F:\Desktop\install.txt
# 更新指定包
pip install --upgrade <>
# 使用镜像源更新
pip install <> -i https://pypi.douban.com/simple
离线安装
除了使用上面的方式联网进行安装外,还可以将安装包也就是wheel格式的文件,下载到本地,然后使用pip进行安装。比如我在PVPL上提前下载的pillow库的wheel文件,后缀名为.whi
网址: https://www.lfd.uci.edu/~gohlke/pythonlibs/
安装
pip install F:\Download\ad3-2.2.1-cp39-cp39-win_amd64.whl
编辑器
- python自带的IDEL
- Visual Studio Code
- Subline Test
- Vim(Linux环境)
- PyCharm(项目中使用) 教育版: https://www.jetbrains.com/edu-products/download/#section=pycharm-edu
基本语法
使用注释
单行注释
# 注释1
# 注释2
# 注释3
块注释
PS python中没有明确的多行注释
可以使用三个连续的单引号'''或者三个连续的双引号"""注释多行内容 英文字符
'''
adasdad
'''
""""
asdasd
""""
语法与缩进
-
python标准语言中不需要分号。简单的换行表示语句结束
-
代码块中有判断、循环、函数、类等代码块,代码块首行通常以关键字开始,冒号结束
if expression: pass elif expresssion: pass else: pass -
使用缩进(四个空格)表示代码块,不需要大括号
-
多行语句使用反斜杠()实现
string = "adas"\ + "adas" -
pass语句 占位 保证语法的正确性
使用场景
- 当代码还没写
- 语法必须而无实现要求
- ...
def func(a,b): pass
使用类
定义类 在 Python 中也可以在 if 语句的分支或者函数定义中定义类。
class <类名>:
<语句1>
<语句2>
...
<语句3>
class human: # 定义 human 类
age = 0 # 定义 age 属性
sex = '' # 定义 sex 属性
height = 0 # 定义 height 属性
weight = 0 # 定义 weight 属性
name = '' # 定义 name 属性
# 类还可以通过继承的形式来进行定义。通过类继承来定义类的基本形式如下。
class <类名>(父类名):
<语句1>
<语句2>
...
<语句3>
# 使用
class student(human): # 通过继承 human 类创建 student 类
school = '' # 定义 weight 属性
number = 0 # 定义 weight 属性
grade = 0 # 定义 weight 属性
在 Python 中需要注意的是,虽然类首先需要实例化,然后才能使用其属性。但实际上当创建一个类以后就可以通过该类名访问其属性。如果直接使用类名修改其属性,那么将影响已经通过该类实例化的其他对象。演示代码如下。
class A: # 定义类 A
name = 'A' # 定义属性 name 将其赋值为 'A'
num = 2 # 定义 num 属性将其赋值为 2
print(A.name) # 直接使用类名访问类的属性
print(A.num) # 直接使用类名访问类的属性
a = A() # 生成 a 对象
print(a) # 查看对象 a
print(A.name) # 查看 a 的 name 属性
b = A() # book 类实例化生成 b 对象
print(b.name) # 查看 b 的 name 属性
A.name = 'B' # 使用类名修改 name 属性
print(a.name) # a 对象的 name 属性被修改
print(b.name) # b 对象的 name 属性也被修改
b.author = 'Butter' # 设置 b 对象的 author 属性
b.price = 15 # 设置 b 对象的 price 属性
print(b.price) # 访问 b 对象的 price 属性
print(a.price) # 访问 a 对象的 price 属性,没有发生改变
import关键字可以导入一个工具包,在python中不同的工具包,提供有不同的工具
使用方法
def 定义一个方法
如果方法没有加return的话,那么会默认返回一个None
在python中除了0和none之外一切为真。
def <方法名>(<参数,可以不设置>):
<语句1>
<语句2>
return 0
实例
In [ 15 ]: def add(a, b):
...: res = a + b
...: print (res)
...:
In [ 16 ]: add( 25 , 53 )
78
使用变量
特性
- 在 python 中定义变量是不需要指定类型
- 在内存中创建一个变量会包括:变量名称、变量保存数据、变量保存数据的类型、变量地址
标识符命名要求:
- 名字需要有见名知义的效果
- 标识符可以由字母,下划线和数字组成
- 不能以数字开头
- 不能与关键字重名
Python中的标识符是区分大小写的
变量使用要求
- 在定义变量时,为了保证代码格式, = 的左右两边该各保留一个空格
- 在python中,如果变量名需要由两个或多个单词组成,可以按照以下方式命名(python中常用
- 每个单词都使用小写字母
- 单词与单词之间使用_下划线连接
- 例如:first_name,last_name….
小驼峰命名法 ---> 方法命名,变量 第一个单词以小写字母开始,后续单词的首字母大写 大驼峰命名法 ----> 类命名
实例
firust = 'apple'
price = 20
a = 1;b = 2 #多个变量赋值
输入与输出
string = input("please input something:")# 输入函数 保存为字符串
a = "tom"
print("you enter %s"%a) # 字符串格式化输出 you enter tom
b = 12
print("you enter %d"%b) # 整数格式化输出 you enter 12
使用常量
Python并未提供如C/C++/Java一样的const修饰符,换言之,python中没有常量,python程序一般通过约定俗成的变量名全大写的形式表示这是一个常量。
python提供了新的方法实现常量:即通过自定义类实现常量。这要求符合“命名全部为大写”和“值一旦被绑定便不可再修改”这两个条件。
# -*- coding: utf-8 -*-
# python 3.x
# Filename:const.py
# 定义一个常量类实现常量的功能
#
# 该类定义了一个方法__setattr()__,和一个异常ConstError, ConstError类继承
# 自类TypeError. 通过调用类自带的字典__dict__, 判断定义的常量是否包含在字典
# 中。如果字典中包含此变量,将抛出异常,否则,给新创建的常量赋值。
# 最后两行代码的作用是把const类注册到sys.modules这个全局字典中。
class _const:
class ConstError(TypeError):pass
def __setattr__(self,name,value):
if name in self.__dict__:
raise self.ConstError("Can't rebind const (%s)" %name)
self.__dict__[name]=value
const = _const()
const.PI=3.14
print(const.PI)
实现2
class _const:
class ConstError(Exception):pass
class UpperCaseError(ConstError):pass
def __setattr__(self,name,value):#拦截属性设置
if name in self.__dict__.keys():#判断属性是否存在
raise self.ConstError("can't bind const")
if not name.isupper():
raise self.UpperCaseError("the '%s' is not all uppercase"%name)
self.__dict__[name]=value
import sys
sys.moduels[__name__]=_const()#将类生成的实例绑定到模块名const 直接使用const来操作常量
#文件名const.py
测试
import const
const.V=7
const.test=10
#此处报绑定大小写错误
print(const.V)
const.V=5
#此处会报错
print(const.V)
使用列表和数组
-
列表(List)定义
B =[] B.append([2,3,3]) B.append([4,45,67]) print(B) print(B[1][2])[[2, 3, 3], [4, 45, 67]] 67 -
数组np.array定义 np.array是不能使用append的
A = np.zeros((2,3)) print(A)结果
[[0. 0. 0.] [0. 0. 0.]] -
List转np.array
C = np.array(B) print(C) print(C[1,2]) print(C[1][2])结果
[[ 2 3 3] [ 4 45 67]] 67 67 -
List或者np.array取值
# List必须使用 [ i ][ j ] 这种形式 print(B[1][2]) #np.array可以使用 [ i ][ j ] 或者 [ i, j ] 两种形式 print(C[1,2]) print(C[1][2]) # 所以为避免胡乱,你可以都使用 [ i ][ j ] 这种形式
命名规范
下划线命名
Python命名约定
# 单前导下划线:_var
# 告知其他程序员:以单个下划线开头的变量或方法仅供内部使用。
# 通配符从模块中导入 Python不会导入带有前导下划线的名称
def _internal_func():
return 42
############
# 单末尾下划线:var_
# 单个末尾下划线(后缀)是一个约定,用来避免与Python关键字产生命名冲突。PEP 8解释了这个约定。
def make_object(name, class_):
... pass
############
# 双前导下划线:__var
# 双下划线前缀会导致Python解释器重写属性名称,以避免子类中的命名冲突,防止变量在子类中被重写。
# 这也叫做名称修饰(name mangling) - 解释器更改变量的名称,以便在类被扩展的时候不容易产生冲突。
############
# 双前导和末尾下划线:__var__
# 由双下划线前缀和后缀包围的变量不会被Python解释器修改:
# Python保留了有双前导和双末尾下划线的名称,用于特殊用途。例子有,__init__对象构造函数,或__call__ --- 它使得一个对象可以被调用。
# 这些dunder方法通常被称为神奇方法 最好避免在自己的程序中使用以双下划线(“dunders”)开头和结尾的名称,以避免与将来Python语言的变化产生冲突。
class PrefixPostfixTest:
def __init__(self):
self.__bam__ = 42
############
# 单下划线:_
# 单个独立下划线是用作一个名字,来表示某个变量是临时的或无关紧要的
def _add(a, b):
_ = a + b
return _
###########
数据类型
数据类型
数据类型可以分为数字型和非数字型
-
数字型
- 整型(int) 长度32位
可以作为Long类型使用 可以使用八进制、十六进制、二进制
a = 1 int("3") # 转成int类型 参数为字符报错 只保留整数,不进位 id(-1) # 查看内存地址- 浮点型(float)
a = 1.121212 float("3") # 强转为浮点数- 复数
复数由实数部分和虚数部分构成,用a+bj或complex(a,b)表示,复数的实数部a和虚数部b都是浮点数
complex(x) # x转换为复数,实数部分为x,虚数部分为0 complex(x,y) # x,y转换为复数,实数部分为x,虚数部分为y
数学计算
import math
math.ceil(x) # 返回数字的上入整数 ceil(4.1) = 4
math.floor() # 返回数字的下舍整数 floor(4.9) = 4
math.round(x [,n]) # 返回浮点数x的四舍五入值,n表示保留位数
math.hypot(x,y) # 返回欧几里得范数 sprt(xx + yy)
math.abs()
...
-
非数字型
- 布尔
(boolean)大小写注意
1 >= True
0 == False
a = True
b = False
not a # False
bool(a) # True 判断真假
bool(None) # False None不是boolean
-
Bytes
```
-
字符串(string)
字符串需要用单引号 ’ ’ 或双引号 " " 括起来,是一种特殊的元组。不能改变字符串中的某个元素的值
基础操作:索引、切片、乘法-多次输出、成员资格检查、长度len()、最大值、最小值
str = 'Hello'
print(str[0]) # H
# 长度
len(str)
# 查找内容 find
print(str_.find('l')) # 2
# 判断 startswith,endswith
print(str_.startswith('H')) # True
print(str_.endswith('H')) # False
# 计算 count 在[start,end)之间 sub出现的次数
print(str_.count('l', 0, 3)) # 1
# 替换 replace
print(str_.replace('o', '4')) # Hell4
# 切割 split
print(str_.split('e')) # ['H', 'llo']
print(str_.split('l')) # ['He', '', 'o']
# 修改大小写 upper lower
print(str_.upper()) # HELLO
print(str_.lower()) # hello
# 空格处理 strip
str_ = " Hello world "
print(str_) # Hello world
print(str_.strip()) # Hello world
print(str_.strip(' Hello')) # world
# 字符串拼接 join
str_ = ','
print(str_.join(['a', 'b', 'c'])) # a,b,c
str_ = ''
print(str_.join(['a', 'b', 'c'])) # # abc
-
字典(dictionary)
字典的每个元素是键值对,无序的对象集合,是可变容器模型,且可存储任意类型对象
字典可以通过键来引用,键必须是唯一的且键名必须是不可改变的(即键名必须为Number、String、元组三种类型的某一种),但值则不必
字典是使用 { } 大括号包含键值对
dict = {'name': 'steve', 'age': 18}
print(dict)
dict['name'] # 'steve' 根据键名访问 不存在报错
dict.get('name') # 通过get()访问值 不存在返回None
dict.pop('name') # 获取指定 key 对应的 value,并删除这个 key-value 对。
dict['name'] = 'aa' # 修改
dict.update({'name':'tom'}) # 修改,若键不存在,则添加
del dict['name'] # 删除
dict.clear() # 清空字典
print('name' in dict) # 判断键名是否存在
###
man={'name':'james','age':12}
# 获取所有键值对
print(man.items()) # 结果为: dict_items([('name', 'tom'), ('age', 12), ('sex', 'man')])
# 获取所有d键
print(man.keys()) # 结果为 dict_keys(['name', 'age', 'sex'])
# 获取所有值
print(man.values()) # 结果为 dict_values(['tom', 12, 'man'])
###
# 当程序要获取的 key 在字典中不存在时,该方法会先为这个不存在的 key 设置一个默认的 value,然后再返回该 key 对应的 value
cars = {'BMW': 8.5, 'BENS': 8.3, 'AUDI': 7.9}
# 设置默认值,该key在dict中不存在,新增key-value对
print(cars.setdefault('PORSCHE', 9.2)) # 9.2
print(cars)
# 设置默认值,该key在dict中存在,不会修改dict内容
print(cars.setdefault('BMW', 3.4)) # 8.5
print(cars)
###
# 使用给定的多个 key(可以为列表、元组) 创建字典,这些 key 对应的 value 默认都是 None;也可以额外传入一个参数作为默认的 value
# 使用列表创建包含2个key的字典
a_dict = dict.fromkeys(['a', 'b'])
print(a_dict) # {'a': None, 'b': None}
# 使用元组创建包含2个key的字典
b_dict = dict.fromkeys((13, 17))
print(b_dict) # {13: None, 17: None}
# 使用元组创建包含2个key的字典,指定默认的value
c_dict = dict.fromkeys((13, 17), 'good')
print(c_dict) # {13: 'good', 17: 'good'}
-
元组(tuple)
tuple 是使用 ( ) 小括号包含各个数据项,可以在元组中放入另一个元素 tuple 与 list 的唯一区别是 tuple 的元素是不能修改,而 list 的元素可以修改
tuple1 = (True, 1, 'Hello') # 创建一个元组 print(tuple1) # (True, 1, 'Hello') tuple = (1,'2',(3,)) tuple2 = (1,) # 创建单元素元组时,不能省略, tuple1[0] # 获取元素 tuple1[::-1] # 元组反转 # 元组重复操作与列表类似 # 添加元组 tuple1 += (4,) # 末尾添加 tuple1 = tuple1[:2] +(3,) + tuple[2:] # 指定位置添加 # 删除元组 tuple1 = tuple1[:2] + tuple1[3:] # 通过拼接进行删除 del tuple1 # 删除元组 tuple1.count(5)# 元素出现次数 tuple1.index('True') # 元素第一次c -
列表 有序的可重复元素集合
可以嵌套、迭代、修改、分片、追加、删除、成员判断
列表是一个可变成都的顺序存储结构,每个位置存放的都是对象的指针
类似于List集合
# 创建列表,,不同数据项用逗号隔开 list = [1,'2',3.12] # 访问数据 list[0] # 1 len(list) # 列表长度 # 修改元素 list[1] = 2 # 删除元素 可以使用del语句或者remove(),pop()删除指定元素 删除后索引自动更新 del list[0] # 根据下标删除 list.pop() # 删除列表最后一个元素 list.remove(3) # 根据元素值删除列表中数据 # 列表拼接 重复值不排除 list + [1,2] # 最值 max(list) min(list) # 序列转换为列表 list(seq) # 列表反转 list[::-1] # 返回反转后结果 list.reverse() # 将反转结果更新列表 list.append('d') # 追加 list.insert(1,'d') # 指定位置追加 list.extend([1,2,3]) # 列表拼接 str_ = ''.join(list) # 列表转str -
集合(set)
set 是一个无序不重复元素的序列
使用大括号 { } 或者 set() 函数创建集合 操作:用 set() 创建一个空集合、使用 set 可以去重
set1 = {'me', 'you', 'she', 'me'} print(set1)# {'me', 'she', 'you'} set1.add('22') # 添加 set1.update([10,37,42]) # 在s中添加多项 set1.remove('H')# 删除一项 len(set1) # set长度 set1.pop() # 删除,并返回第一个值
切片
也叫截取,指对序列进行截取,选取序列中的某一段;语法:list[start : end]
start起始索引,省略表示从0开始, end结束索引,省略表示直到列表结束 ;区间包含start不包含end
list = [1,2,3,4]
list[1:3] # [2, 3]
list[:] # [1, 2, 3, 4]
list[:2] # [1, 2]
list[1:2:3] # [2]
None 空值
算术运算符
运算与java基本一致
加
1 + 2 # 3
减
2-1 # 1
乘
2 * 4 # 8
2 ** 4 # x的y次幂 16
除
# 结果为浮点数
9/3 # 3.0
# 只取结果整数部分 小数部分抛弃
10//3 # 3
# 余数计算
10%3 # 1
# 同时得到商和余数
divmod(10,3) # (3, 1)
赋值运算
c = a + b # 赋值
c += a
c -= a
c *= a
c /= a # 等价 c = c/a
c %= a
c **= a
c //= a # c = c//a
逻辑运算
a = 10;b = 20
(a and b) # 20 (a and b) a为True 返回b; a为False或0 返回a
(a or b) # 10 (x or y) a不等于0或为True 返回a; a等于0或Fasle 返回y
not(a and b) # False 取反 返回True或False
成员运算符
用于判断对象是否在某个集合中 返回True 或 False
a in list # 如果a在y中 返回True
a not in list # a不在y中 返回True
身份运算符
用于判断是否引用自同一个对象
a is b # 如果a与b都引用自同一个对象 返回True 基本类型大多数值相同对象相同
a is not b # 相反值
三目运算
a = 1
b = 2
h = ""
h = a-b if a>b else a+b # 如果a>b返回True 执行a-b,否则执行a+b
方法
基本结构:
def <方法名>(<...参数>):
pass
retrun <value>
# 调用方法
<方法名>(<...参数>)
主方法:定义的方法应在主方法之前
if __name__ == '__main__':
print("this is main function")
参数
def test2_1(a, b):
print('test2_1', a)
return a + b # 实参
def test2_2(a, b): # 形参
a += 2
print('test2_2', a) # 形参
return test2_1(a, b) # 实参
特殊参数
# args 为元组
def func_1(self, *args, flag='flag'):
print(self)
print(args)
print(flag)
print(type(args))
# args 为字典 后面不可加参数
def func_2(self, **args):
print(self)
print(args.get('test'))
print(type(args))
# 合用,表输入任意参数
def func_3(*args, **kwargs):
print(args)
print(kwargs)
if __name__ == '__main__':
func_1("abc", 1, 2, 3, flag='this flag')
print('-' * 10)
func_2("abc", name='aa', test='test')
print('-' * 10)
func_3(1, 2, 3, 4, arr='args', name='test')
print('-'*10)
func_3()
for循环
# for <item> in <可迭代变量>:
# pass
for i in [1,2,3,4]
print(i)
# for循环嵌套
for i in [1,2,3]:
for n in [2,3,4]:
pass
pass
If判断
# if <boolean表达式>:
# pass
# elif <boolean表达式>:
# pass
# else:
# pass
While循环
while <boolean表达式>:
passz
range()
创建一个整数列表,一般用在 for 循环中。
# 循环输出0-10
for i in range(10):
print(i)
# 循环输出2-10
for i in range(2,10):
print(i)
递归
# 递归函数
def recursion_test(num):
if num == 0:
return 0
elif num >= 997:
print("最大值不超过1000")
exit()
return num + recursion_test(num - 1)
匿名函数
lambda: int(string) + 10
# 实例
def lambda_test(string):
return lambda: int(string) + 10
# 参数func默认值为None,调用时可省略不写
def lambda_test2(a, b, func=None):
if func is None:
return a + b
return func(a, b)
语法糖
# 语法糖
list1 = [x for x in range(10) if x % 2 != 0]
list2 = {x: str(x + 1) for x in range(10) if x % 2 != 0}
list3 = {x for x in range(10) if x % 2 != 0}
list4 = [lambda x: x + i for i in range(10)]
print(list4[0](10))
生成器
# yield标志该方法为生成器
def createNum():
a, b = 0, 1
for c in range(10):
yield b
a, b = b, a + b
# 使用
s1 = createNum()
s2 = createNum()
while True:
print(next(s1)) # 调用方式一
print(s1.__next__()) # 调用方式二
装饰器
# 内部验证
def w1(func):
def inners():
print("check...")
func()
return inners
@w1 # 装饰器 在程序一开始即执行
def test_1():
print("test")
# 调用
if __name__ == '__main__':
test_1()
##########
异常处理
"""
try:
pass
except:
pass
"""
try:
print(1 / 0)
except Exception as e:
print(e)
"""
except: #捕获所有异常
except: <异常名>: #捕获指定异常
except:<异常名1,异常名2):捕获异常1或者异常2
except:<异常名>,<数据>:捕获指定异常及其附加的数据
except:<异常名1,异常名2>:<数据>:捕获异常名1或者异常名2,及附加的数据库
"""
"""
AttributeError 调用不存在的方法引发的异常
EOFError 遇到文件末尾引发的异常
ImportError 导入模块出错引发的异常
IndexError 列表越界引发的异常
IOError I/O操作引发的异常,如打开文件出错等
KeyError 使用字典中不存在的关键字引发的异常
NameError 使用不存在的变量名引发的异常
TabError 语句块缩进不正确引发的异常
ValueError 搜索列表中不存在的值引发的异常
ZeroDivisionError 除数为零引发的异常
"""
断言
# 语法格式
expression assert 表达式
"""
assert语句用来声明某个条件是真的。
如果你非常确信某个你使用的列表中至少有一个元素,而你想要检验这一点,并且在它非真的时候引发一个错误,那么assert语句是应用在这种情形下的理想语句。
当assert语句失败的时候,会引发一AssertionError。
"""
assert expression [, arguments]
assert 表达式 [, 参数]
# 自定义异常
class ShortInputException(Exception):
'''自定义的异常类'''
def __init__(self, length, atleast):
#super().__init__()
self.length = length
self.atleast = atleast
def main():
try:
s = input('请输入 --> ')
if len(s) < 3:
# raise引发一个你定义的异常
raise ShortInputException(len(s), 3)
except ShortInputException as result:#x这个变量被绑定到了错误的实例
print('ShortInputException: 输入的长度是 %d,长度至少应是 %d'% (result.length, result.atleast))
else:
print('没有异常发生.')
main()
文件
# open(<绝对路径>, <访问模式>)
# 写文件
# fp = open('text.text', 'w') # 文件流 写模式
# fp.write([1,2,3])
# fp.close() # 关闭文件流
# 读文件
# fp = open('text.text', 'r') # 文件流 读模式
# context = fp.readlines() # 读取所有行,输出列表
# context = fp.read(<n>) # 读取一行,默认0
# print(context)
# fp.close() # 关闭文件流
# 序列化
import json
# fp = open('text.text', 'w')
# tem = [1, 2, 3, 4]
# json.dump(tem, fp) # 序列化
# fp.close() # 关闭文件流
# 反序列化
# 捕获异常
try:
fp = open('text.text', 'r')
res = json.load(fp)
print(res)
print(type(res))
fp.close()
except FileNotFoundError as e:
print("error")
# 自动关闭流操作
with open('text.text', 'r') as fp:
print(fp.readlines())
访问模式
| 访问模式 | 说明 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,则报错。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说.新的内容将会被写入到R有内容之后。如果该文件不存在.创建新文件讲行写入. |
网络
基本概念
概述
Https协议: HTTP+SSL(安全套间层)
互联网上使用的 HTTP协议是明文的,存在很多缺点——比如传输内容会被偷窥(嗅探)和算改。发明SSL协议,就是为了解决这些问题。
作用: 1.验证服务器是不是我们想要访问的服务界 2.数据传输过程中,进行数据加密
爬虫时需要关注点;ssl验证设置为:verify=False
URL形式
URL的形式: scheme://host[:port#]/path/.../[?query-string][#anchor]
- scheme:协议(例收: http、https、ftp)
- host: 服务器的IP地址或域名
- path: 访问资源的路径
- query-string: 参数,发送给http服务器的数据
- anchor: 锚(跳转到网页的指定锚点位置)
e.g:
- http: / / localhost:4000/file/part01/1.2.html
- http: //item.jd.com/11936238.html#product-detail
常见请求方式
-
GET
数据请求
-
POST
表单提交,长数据获取
相应状态码
-
1xx:指示信息 -- 表示请求已接收,继续处理
-
2xx:成功 ------ 表示请求已被成功接收、理解、接受
- 3xx:重定向 ---- 要完成请求必须进行更进一步的操作
- 4xx:客户端错误--请求有语法错误或请求无法实现
- 5xx:服务器端错误--服务器未能实现合法的请求
# 常见状态代码、状态描述、说明:2e0 oK
# 客户端请求成功
200 OK # 客户端请求成功
302 redirect # 重定向
400 Bad Request # 客户端请求有语法错误,不能被服务器所理解
401 Unauthorized # 请求未经授权,这个状态代码必须和wwl-Authenticate报头域一起使用
484 Not Found # 请求资源不存在,eg:输入了错误的URL
500 Internal Server Error # 服务器发生不可预期的错误
503 Server Unavailable # 服务器当前不能处理客户端的请求,一段时间后可能恢复正常
服务器返回给浏览器的格式
response
HTTP/1.1 288 oK
Bdpagetype: 2
Bdqid: exf73ec47900013621
Cache-Control : private
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type:text/html;charset-utf-8
Date: Sun,18 Nov 2018 08:37:32GMT
Expires: Sun,18 Nov 2018 88:37:32GMT
Server: BWS/1.1
Set-Cookie: BDSVRTN-251;path=/
Set-Cookie: BD_HOME-1;path=/
Set-Cookie: H_PS_PSSID=1445_21097_27400_27508; path=/;domain=.baidu.com
Strict-Transport-Security: max-age-172888
X-Ua-Compatible: IE=Edge , chrome=1
Transfer-Encoding: chunked
爬虫
概念
概述
目标:抓取网站中需要的数据
核心:
- 爬取网页:爬取整个网页,包含网页中所有的内容
- 解析数据:将网页中得到的数据进行解析
- 难点:爬虫与反爬虫之间博弈
用途:
- 数据分析、人工数据集
- 社交软件冷启动
- 舆情监控
- 竞争对手监控
相关库:requests:发送网络请求,返回响应数据
- requests的底层实现就是urllib
- requests在Python2和Python3通用,方法完全一样
- requests简单易用
- requests能够自动帮助我们解压(gzip压缩的)网页内容
Robots协议
一个约定成俗的协议,指明robots.txt文件
指明爬虫可以爬取的网页权限,说明本网站哪些内容不可以被抓取。起不到简直作用
一般只有大型搜索引擎才会遵守。
爬虫类型
-
通用爬虫
功能:访问网页 -> 抓取数据 -> 数据存储 -> 数据处理 -> 提供检索服务
网站排名(SEO):
- 根据pagerank算法值进行排名(参考网站流量、点击率等)
- 竞价排名
缺点:
- 抓取的数据大多是无用的
- 不能根据用户的需求来精确获取数据
-
聚焦爬虫
功能:针对特定网站的爬虫,根据需求实现爬虫程序抓取需要的数据
设计思路:
- 确定要爬取的url
- 模拟浏览器通过http协议访问,,获取html代码
- 解析html字符串(根据一定规则提取需要的数据)
反爬虫手段
-
User-Agent:
用户代理,简称UA。是一个特殊字符串头,使得服务器能识别客户使用的操作系统及版本、CPU类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等
-
代理IP
- 透明代理: 对方服务器可以知道你使用代理,且知道你的真实IP
- 匿名代理: 对方服务器可以知道你使用代理,但不知道你的真实IP
- 高匿代理: 对方服务器不知道你使用代理,且不知道你的真实IP
-
验证码访问
打码平台:云打码平台
-
动态加载网页
网站返回js数据,并不是网页的真实数据
selenium驱动真实浏览器发送请求
-
数据加密
分析js代码
urllib库
urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了urllib。urllib中一共有四个模块,分别如下:
- urllib.request:用于打开和阅读URL
- urllib.error:包含由引发的异常urllib.request
- urllib.parse:用于解析URL
- urllib.robotparser:用于解析robot.txt文件
实例
import urllib.request
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url)
context = response.read().decode('utf-8')
# with open('baidu.html', 'w', encoding='utf-8') as fp:
# fp.write(context)
# response.readline() # 读取一行
# response.readlines() # 按行读取
print(response.getcode()) # 响应码
# print(response.headers) # 请求头
# print(response.getheaders()) # 响应头
# print(response.geturl()) # 请求地址
下载
url_page = 'http://www.baidu.com'
# response = urllib.request.urlretrieve(url_page, 'baidu.html')
urllib.request.urlretrieve('https://img-home.csdnimg.cn/images/20210917084230.jpg', 'test.png')
包装请求对象
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
url = 'https://www.baidu.com'
request = urllib.request.Request(url, headers=header)
response = urllib.request.urlopen(request)
context = response.read().decode('utf-8')
print(context)
编解码
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
url = 'https://www.sogou.com/web?'
# print(parse.quote('测试')) # 编码
data = {'ie': 'UTF-8', 'query': '测试'}
# print(url + parse.urlencode(data)) # 参数编码
url = url + parse.urlencode(data)
request = urllib.request.Request(url, headers=header)
response = urllib.request.urlopen(request)
context = response.read().decode('utf-8')
print(context)
POST请求
import urllib.parse
import urllib.request
import json
# post请求
url = 'https://fanyi.baidu.com/sug'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
data = {
'kw': 'spider'
}
data = urllib.parse.urlencode(data).encode('utf-8') # post参数传入请求对象中
request = urllib.request.Request(url, data, header)
response = urllib.request.urlopen(request)
context = response.read().decode('utf-8')
print(json.loads(context))
代理
代理IP: http://www.66ip.cn/nm.html
使用handler、opener对象请求
url = 'http://www.baidu.com'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
request = urllib.request.Request(url, headers=header)
handler = urllib.request.HTTPHandler() # 获取handler对象
opener = urllib.request.build_opener(handler) # 获取opener对象
response = opener.open(request) # 调用opener对象获取response
context = response.read().decode('utf-8')
with open('baidu.html', 'w', encoding='utf-8') as fp:
fp.write(context)
代理服务器
1.代理的常用功能?
1.突破自身IP访问限制,访问国外站点。
2.访问一些单位或团体内部资源
扩展:某大学FTP(前提是该代理地址在该资源的允许访问范围之内),使用教育网内地址段免费代理服
务器,就可以用于对教育网开放的各类FTP下载上传,以及各类资料查询共享等服务。
3.提高访问速度
扩展:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲
区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度。
4.隐藏真实IP
扩展:上网者也可以通过这种方法隐藏自己的IP,免受攻击。
2.代码配置代理
创建Reuqest对象
创建ProxyHandler对象
用handler对象创建opener对象
使用opener.open函数发送请求
import random
import urllib.request
url = 'http://www.baidu.com'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
# 代理池
proxies_pool = [
{'http': '121.230.210.168:3256'},
{'http': '211.65.197.93:80'},
{'http': '114.230.107.75:3256'},
{'http': '117.88.246.178:3000'},
]
# 随机选择一个其中一条代理IP
proxies = random.choice(proxies_pool)
request = urllib.request.Request(url, headers=header)
handler = urllib.request.ProxyHandler(proxies=proxies) # 获取handler对象
opener = urllib.request.build_opener(handler) # 获取opener对象
response = opener.open(request) # 调用opener对象获取response
解析
常用工具
-
xpath
import random import urllib.request from lxml import etree url = 'http://www.baidu.com' header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'} request = urllib.request.Request(url, headers=header) handler = urllib.request.HTTPHandler() # 获取handler对象 opener = urllib.request.build_opener(handler) # 获取opener对象 response = opener.open(request) # 调用opener对象获取response html_tree = etree.HTML(response.read().decode('utf-8')) # 网页数据 data = html_tree.xpath('//img[@id="s_lg_img"]/@src') # 选择性解析的列表 img_url = "https:" + data[0] # 图像地址 urllib.request.urlretrieve(img_url, 'baidu.png') # 下载图像 -
JsonPath
参考博客:https://blog.csdn.net/luxideyao/article/details/77802389
-
BeautifulSoup
""" 简称:bs4 优点:接口设计人性化,使用方便 缺点:效率没有lxml效率高 """from bs4 import BeautifulSoup soup = BeautifulSoup(open('baidu.html', encoding='utf-8'), 'lxml') print(soup.title.text) # 获取标签属性 print(soup.title) # 获取标签bs4的方法使用
soup = BeautifulSoup(open('baidu.html', encoding='utf-8'), 'lxml') # print(soup.title.text) # find() find_all() ######### # print(soup.find('a')) # 返回 第一个a标签 # print(soup.find('a', title='a')) # 返回第一个title值为‘a’的a标签, # print(soup.find_all('input')) # 查询所有input # print(soup.find_all('input', limit=2)) # 查询前两个input # print(soup.find_all(['input', 'img'])) # 查询多个 # select() ################### # select() 返回列表,查询多个数据 # .<> 代表class -> 类选择器 # #<> 代表id -> id选择器 # print(soup.select('#c-tips-container')) # print(soup.select('.wrapper_new')) # print(soup.select('li[id]')) # 查询li标签中有id的标签 # print(soup.select('li[id="l2"]')) # 查询li标签中id为l2的标签 # print(soup.select('div li')) # div下的li # print(soup.select('div > ul > li')) # 某标签下的第一级子标签 # print(soup.select('a,div')) # 查询多个 # 获取节点信息 ################# content = soup.select("meta[name='description']")[0] # print(content.string) # 如果标签对象中除了内容还有标签,那string就获取不到数据,而get_text()可以获取数据 print(content.get_text()) # 获取标签内容 # 获取标签属性 三种方式 print(content.attrs.get('content')) # 推荐使用 print(content.attrs.get('content')) print(content['content'])
Selenium
概述
- Selenium是一个web应用程序测试工具
- 测试直接运行在浏览器中,就像真正用户操作
- 支持通过各种driver(FirfoxDriver, IternetExplorerDriver, OperaDriver, ChromeDriver)驱动真实浏览器完成测试
- 支持无界面浏览器操作
作用:模拟浏览器功能,自动执行网页中的js代码,实现动态加载 chrome浏览器驱动:http://chromedriver.storage.googleapis.com/index.html
驱动与版本映射表:http://blog.csdn.net/huilan_same/article/details/51896678
使用
基本使用
from selenium import webdriver
# 操作浏览器驱动对象
driver_path = 'chromedriver.exe'
browser = webdriver.Chrome(driver_path)
# 访问网址
url = 'http://www.baidu.com'
browser.get(url)
# 获取网页源码
content = browser.page_source
print(content)
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先要找到它们,webDriver提供很多定位元素的方法
import time
from selenium import webdriver
# 操作浏览器驱动对象
driver_path = 'chromedriver.exe'
browser = webdriver.Chrome(driver_path)
# 访问网址 ################
url = 'https://www.baidu.com'
browser.get(url)
# 获取网页源码
# content = browser.page_source
# print(content)
# 定位元素 ################
# eg_btn = browser.find_element_by_id('su')
# eg_btn = browser.find_element_by_name('wd')
# eg_btn = browser.find_element_by_xpath('//input[@id="su"]')
# eg_btn = browser.find_element_by_tag_name('input')
# eg_btn = browser.find_element_by_css_selector('#kw')[0]
# eg_btn = browser.find_element_by_link_text('新闻')
input_ = browser.find_element_by_id('kw')
# 获取元素信息 #############
# tag_name:标签名
# text:元素文本
# get_attribute(<>) 元素属性
# print(eg_btn.get_attribute('class'), eg_btn.text, eg_btn.tag_name, sep=',') # s_ipt,,input
# 元素交互 #################
# 输入
input_.send_keys('周杰伦')
# 点击
# 获取点击按钮
btn_ = browser.find_element_by_id('su')
btn_.click()
time.sleep(2)
# 模拟js滚动
js_roll = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_roll)
time.sleep(2)
# 获取下一页按钮
btn_next = browser.find_element_by_xpath('//a[@class="n"]')
btn_next.click()
time.sleep(2)
# 后退操作
browser.back()
time.sleep(2)
# 前进操作
browser.forward()
time.sleep(2)
browser.save_screenshot('bai.png') # 保存屏幕快照
# 退出
browser.quit()
无界面浏览器:
Phantomjs: phantomjs.exe
- 支持页面元素查找,js执行
- 不进行CSS和GUI渲染,效率比真实浏览器较高
Chrome handless :Chrome-headless模式,Google针对Chrome浏览器59版新增加的一种模式,可以让你不打开UI界面的情况下使用Chrome浏览器,所以运行效果与 Chrome 保持完美一致。
系统要求
- win: chrome>=60 Unix/Linux: chrome>=59
- python3.6+
- selenium.4.*
- chromeDriver ==2.31
def share_browser():
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# chrome浏览器文件路径: chrome.exe
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
return webdriver.Chrome(options=chrome_options)
url = 'https://www.baidu.com'
browser = share_browser()
browser.get(url)
browser.save_screenshot('save.png')
request库
概述
参考文档: https://cn.python-requests.org/zh_CN/latest/
Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用。
Requests 完全满足今日 web 的需求。
- Keep-Alive & 连接池
- 国际化域名和 URL
- 带持久 Cookie 的会话
- 浏览器式的 SSL 认证
- 自动内容解码
- 基本/摘要式的身份认证
- 优雅的 key/value Cookie
- 自动解压
- Unicode 响应体
- HTTP(S) 代理支持
- 文件分块上传
- 流下载
- 连接超时
- 分块请求
- 支持
.netrc
使用
基本封装
import requests
class requestDemo:
def __init__(self, url):
self._url = url
def run(self):
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
response = requests.get(self._url, headers=header)
print(response.status_code)
response.encoding = 'utf-8'
# response.url # 返回url
# response.status_code # 返回状态码
# response.headers # 返回响应头
# response.content # 返回二进制源码数据
return response.text # 返回源码
@property
def url(self):
return self._url
if __name__ == '__main__':
request_demo = requestDemo('http://www.baidu.com')
# with open('text.html', 'w') as f:
# f.write(requestDemo.run())
text = request_demo.run()
with open('text.html', 'w') as f:
f.write(text)
代理
import requests
# 请求头
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
# 请求路径
url = "https://t7.baidu.com/it/u=1878516430," \
"2044457199&fm=218&app=92&f=JPEG?w=121&h=75&s=918398561EC1284D18B2BC5B03004099 "
url2 = 'http://www.baidu.com/s'
# 请求参数
params = {'wd': 'python'}
# 请求代理
proxies = {'http':'http://118.117.189.75:3256'}
response = requests.get(url2, headers=header, params=params, proxies=proxies)
print(response)
# response.encoding = 'utf-8'
# print(response.text)
print(response.status_code)
# 输出到本地
# with open('logo.png', 'wb') as f:
# f.write(response.content)
get/post请求
"""
get和post区别?
1: get请求的参数名字是paramspost请求的参数的名字是data
2:请求资源路径后面可以不加?
3:不需要手动编解码
4:不需要做请求对象的定制
"""
# get请求
import requests
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
url = 'https://www.baidu.com/s'
data = {
'wd': '北京'
}
response = requests.get(headers=header, params=data, url=url)
print(response.text)
# post请求
import json
import requests
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'eye'
}
response = requests.post(headers=header, data=data, url=url)
content = response.text
obj = json.loads(content)
print(obj)
验证码破解: 超级鹰打码平台
Scrapy
概述
scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
安装:pip instal scrapy
安装时常出现错误的原因可能是因为没安装依赖库:
twisted手动安装:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
报错:win32错误
解决:
pip install pypiwin32Anaconda
1、anaconda 是一个python的发行版,包括了python和很多常见的软件库, 和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易。
2、Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项
在安装完成之后会多几个应用
- Anaconda Navigtor :用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在 Navigator 中手工实现。
- Jupyter notebook :基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程。
- qtconsole :一个可执行 IPython 的仿终端图形界面程序,相比 Python Shell 界面,qtconsole 可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
- spyder :一个使用Python语言、跨平台的、科学运算集成开发环境。
Scrapy创建项目
-
终端输入:
scrapy startproject <项目名>cd /d F:\learning\Python\pythonProject scrapy startproject demo4项目组成
spiders # 存储爬虫文件 __init__.py <自定义爬虫文件>.py # 自己创建 实现爬虫核心功能的核心 __init__.py items.py # 定义爬取的数据结构 middlewares.py # 中间件 代理 pipelines.py # 管道文件,只有一个类用于处理下载数据后续处理,默认300优先级,《值越小优先级越高(1-1000)》 settings.py # 配置文件 e.g:是否遵循robots协议、User-Agent定义等 -
创建按爬虫文件
cd /d F:\learning\Python\pythonProject\demo4\spiders scrapy genspider <爬虫名字> <网页域名>爬虫文件基本组成
继承scrapy.Spider类 name = 'baidu' # 运行爬虫文件时使用的名字 allowed_domains # 爬虫允许的域名,在爬取时不是在该域名下的url会自动过滤 start_urls # 声明爬虫的其实地址,可以写多个url,一般一个 def parse(self,response) # 解析数据的回调函数 response.text # 字符串 response.body # 二进制文件 response.xpath() # selector列表 extract() # 提取的selector对象的data属性值 extract_first() # 提取的是selector列表的第一个数据 -
运行爬虫代码
scrapy crawl <爬虫名字>
Scrapy架构组成
-
引擎
自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
-
下载器
从引擎处获取到请求对象后,请求数据
-
spiders
spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。
换句话说,spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
-
调度器
有自己的调度规则,无需关注
-
管道(Item pipeline)
最终处理数据的管道,会预留接口供我们处理数据
当Item在spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。 每个item pipeline组件(有时称之为“Item Pipeline") 是实现了简单方法的Python类。 他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。 以下是item pipeline的一些典型应用:
- 清理HTMAL数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存到数据库中
工作原理:
Scrapy Shell
scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。 该终端是用来测试xpath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,该终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。 一旦熟悉了scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
安装:pip install ipython
如果您安装了IPython , Scrapy终端将使用IPython(替代标准Python终端)。IPython终端与其他相比更为强大,提供智能的自动补全,高亮输出,及其他特性。
终端操作
scrapy shell www.baidu.com
response.xpath('//input[@id="su"]/@value').extract_first() # '百度一下'
使用
爬虫文件
import scrapy
from demo4.items import Demo4Item
class DangSpider(scrapy.Spider):
name = 'dang'
allowed_domains = ['http://category.dangdang.com/cp01.05.06.00.00.00.html']
start_urls = ['http://category.dangdang.com/cp01.05.06.00.00.00.html']
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
alt = li.xpath('.//img/@alt').extract_first()
img_src = li.xpath('.//img/@data-original').extract_first()
if not img_src:
img_src = li.xpath('.//img/@src').extract_first()
img = 'http:' + img_src
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
# 构建要给item
# 递交pipelines
yield Demo4Item(name=alt, img=img, price=price)
setting文件中开启管道 pipelines
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
# 若需要使用管道,需要手动在配置中开启
class Demo4Pipeline:
# 爬虫文件开始前执行的方法
def open_spider(self):
pass
# item: yield传递的对象
def process_item(self, item, spider):
with open('books.json', 'a+', encoding='utf-8') as fp:
fp.write(str(item).replace("'", '"'))
return item
# 爬虫文件执行完后,执行的方法
def close_spider(self):
pass
输出标准json数据
from scrapy.exporters import JsonItemExporter
class Demo4Pipeline:
# 构造方法
def __init__(self):
# self.json_file = open('data.json', 'w+', encoding='UTF-8')
self.json_file = open('data.json', 'wb')
# 构建 JsonLinesItemExporter 对象,设定不使用 ASCII 编码,并指定编码格式为 'UTF-8'
self.json_exporter = JsonItemExporter(self.json_file, ensure_ascii=False, encoding='UTF-8')
# 声明 exporting 过程 开始,这一句也可以放在 open_spider() 方法中执行。
self.json_exporter.start_exporting()
# 爬虫文件开始前执行的方法
def open_spider(self, spider):
# self.json_file.write('[\n')
pass
# item: yield传递的对象
def process_item(self, item, spider):
# with open('book.json', 'a+', encoding='utf-8') as fp:
# fp.write(str(item).replace("'", '"'))
# item_json = json.dumps(dict(item), ensure_ascii=False)
# self.json_file.write('\t' + item_json + ',\n')
self.json_exporter.export_item(item)
return item
# 爬虫文件执行完后,执行的方法
def close_spider(self, spider):
# self.json_file.write('\n]')
# # 关闭文件
# self.json_file.close()
# **************
# 声明 exporting 过程 结束,结束后,JsonItemExporter 会将收集存放在内存中的所有数据统一写入文件中
self.json_exporter.finish_exporting()
# 关闭文件
self.json_file.close()
进行多页查询
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.05.06.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:
alt = li.xpath('.//img/@alt').extract_first()
img_src = li.xpath('.//img/@data-original').extract_first()
if not img_src:
img_src = li.xpath('.//img/@src').extract_first()
img = 'http:' + img_src
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
# 构建要给item
# 递交pipelines
yield Demo4Item(name=alt, img=img, price=price)
# 多次重复请求
if self.page < 100:
self.page += 1
url = self.base_url + str(self.page) + '-cp01.05.06.00.00.00.html'
# Request()对象 可以传入meta接收字典用于传递数据
yield scrapy.Request(url=url, callback=self.parse)
CrawlSpider
继承自scrapy.spider
CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定链接,然后再想这些链接发送请求
就是说如果爬取王爷后,需要提取链接并再次爬取,可以使用CrawlSpider
提取链接方式
# 使用链接提取器
"""
scrapy.linkextractors.LinkExtractor(
allow=<>, # 正则表达式 提取符合正则的链接
deny=<>, # (不用)正则表达式 不提取符合正则的链接
allow_domains=<>, # (不用)允许的域名
deny_domains=<>, # (不用)不允许的域名
restrict_xpaths=<>, # xpath,提取符合xpath规则的链接
restrict_css=<> # 提取符合选择器规则的链接
)
"""
# 提取链接
link1 = LinkExtractors(allow='list_123_\d+\.html') # 正则用法
url = link1.extract_links(response)
创建爬虫文件
scrapy genspider -t crawl <name> <url>
使用
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from demo5.items import Demo5Item
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['http://www.dushu.com/book/1617_1.html']
rules = (
Rule(LinkExtractor(allow=r'/book/1617_\d+.html'), callback='parse_item', follow=False),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for item in img_list:
name = item.xpath('./@alt').extract_first()
src = item.xpath('./@data-original').extract_first()
yield Demo5Item(name=name, src=src)
爬取数据并写入数据库
pymysql库
爬取读书网
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from demo5.items import Demo5Item
class ReadSpider(CrawlSpider):
name = 'read'
allowed_domains = ['www.dushu.com']
start_urls = ['http://www.dushu.com/book/1617_1.html']
rules = (
# follow为True 是否跟进 表示一直爬取知道爬取结束,按照提取链接规则进行提取
Rule(LinkExtractor(allow=r'/book/1617_\d+.html'), callback='parse_item', follow=True),
)
def parse_item(self, response):
img_list = response.xpath('//div[@class="bookslist"]//img')
for item in img_list:
name = item.xpath('./@alt').extract_first()
src = item.xpath('./@data-original').extract_first()
yield Demo5Item(name=name, src=src)
声明属性
import scrapy
class Demo5Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
src = scrapy.Field()
通道中定义动作
import pymysql
from scrapy.utils.project import get_project_settings
# 打印数据
class Demo5Pipeline:
def process_item(self, item, spider):
print('*' * 10)
print(str(item))
print('*' * 10)
return item
# 第二通道上传数据
class MysqlPipeline:
def open_spider(self, spider):
settings = get_project_settings() # settings['DB_USER']
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.pwd = settings['DB_PWD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.conect()
def conect(self):
self.connect = pymysql.connect(host=self.host,
port=self.port,
user=self.user,
password=self.pwd,
db=self.name,
charset=self.charset)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
sql = 'insert into book(name,src) values("{}","{}")'.format(item.get('name'), item.get('src'))
self.cursor.execute(sql) # 执行sql语句
self.connect.commit() # 提交事务
return item
def close_spider(self, spider):
self.cursor.close()
self.connect.close()
在setting文件中配置数据库数据
DB_HOST = '127.0.0.1'
DB_PORT = 3306
DB_USER = 'root'
DB_PWD = '123456'
DB_NAME = 'subject'
DB_CHARSET = 'utf8'
# 注册自定义通道
ITEM_PIPELINES = {
'demo5.pipelines.Demo5Pipeline': 300,
'demo5.pipelines.MysqlPipeline': 301,
}
日志处理
日志级别
'''
等级从下往上逐级递增 默认日志等级为DEBUG
CRITCAL # 严重错误
ERROR # 一般错误
WARNING # 警告
INFO # 一般信息
DEBUG # 调试信息
settings.py 添加属性指定日志级别
LOG_FILE <输出文件名> 将屏幕显示的信息全部记录到文件中,屏幕不再显示,注意文件后缀一定是.log
LOG_LEVEL <日志等级> 设置日志显示的等级,就是显示哪些,不显示哪些
'''
scrapy的post请求
-
重写start_requests方法():
def start_requests(self) -
start_requests 返回值
# scrapy_FormRequest(url=url, headers=headers, callback=self.parse_item, formdata=data) # url 要发送的post地址 # headers 可以定制头信息 # callback 回调函数 # formdata post所携带的数据(字典类型)
实际使用
import json
import scrapy
class FanyiSpider(scrapy.Spider):
name = 'fanyi'
allowed_domains = ['https://fanyi.baidu.com/sug']
# start_urls = ['http://fanyi.baidu.com/']
#
# def parse(self, response):
# pass
def start_requests(self):
url = 'https://fanyi.baidu.com/sug'
data = {
'kw': 'detail'
}
yield scrapy.FormRequest(url=url, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content = response.text
print(json.loads(content))
scrapy代理
参考1: https://www.pythontab.com/html/2014/pythonweb_0326/724.html
参考2:https://blog.csdn.net/weixin_38819889/article/details/109018429?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163204694616780265464944%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=163204694616780265464944&biz_id=0&spm=1018.2226.3001.4187
方式一: 直接在爬虫程序中设置proxy字段
在自己具体的爬虫程序中设置proxy字段,代码如下,直接在构造Request里面加上meta字段即可
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse,
meta={'proxy': 'http://proxy.yourproxy:port'})
# 添加meta属性,并将代理IP加入proxy
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.css('span small::text').extract_first(),
'tags': quote.css('div.tags a.tag::text').extract(),
}
方式二:使用中间件DownloaderMiddleware进行配置
-
在settings.py文件中,找到DOWNLOADER_MIDDLEWARES它是专门用来用配置scrapy的中间件.我们可以在这里进行自己爬虫中间键的配置,配置后如下:
DOWNLOADER_MIDDLEWARES = { 'WandoujiaCrawler.middlewares.ProxyMiddleware': 100, } # 其中WandoujiaCrawler是我们的项目名称,后面的数字代表中间件执行的优先级。 # 官方文档中默认proxy中间件的优先级编号是750,我们的中间件优先级要高于默认的proxy中间键。 -
中间件middlewares.py的写法如下(scrapy默认会在这个文件中写好一个中间件的模板,不用管它写在后面即可):
# -*- coding: utf-8 -*- class ProxyMiddleware(object): def process_request(self, request, spider): request.meta['proxy'] = "http://proxy.yourproxy:port" """ 1.是proxy一定是要写成 http:// 前缀,否则会出现to_bytes must receive a unicode, str or bytes object, got NoneType的错误. 2.是官方文档中写到process_request方法一定要返回request对象,response对象或None的一种,但是其实写的时候不用return,乱写可能会报错。 另外如果代理有用户名密码等就需要在后面再加上一些内容: """如果代理有用户名密码等就需要在后面再加上一些内容:
# Use the following lines if your proxy requires authentication proxy_user_pass = "USERNAME:PASSWORD" # setup basic authentication for the proxy encoded_user_pass = base64.encodestring(proxy_user_pass) request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass





















