给 Solr 设置字段的时候
老师是这样的:

我也去Solr中所创建core的Managed_schema的加了这段:

然后打开Solr : localhost:8983 后报错
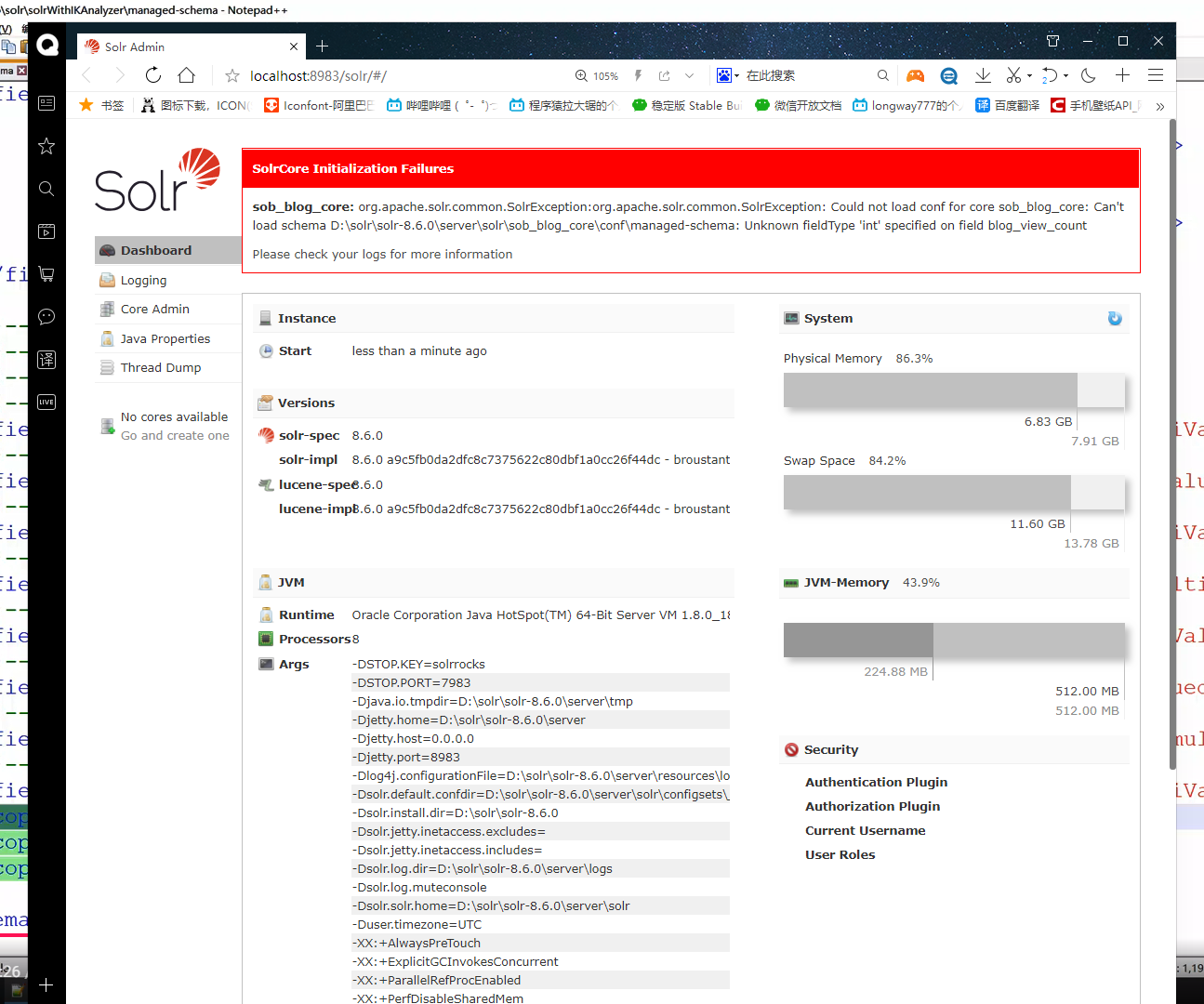
报错细节:
sob_blog_core: org.apache.solr.common.SolrException:org.apache.solr.common.SolrException: Could not load conf for core sob_blog_core: Can't load schema D:\solr\solr-8.6.0\server\solr\sob_blog_core\conf\managed-schema: Unknown fieldType 'int' specified on field blog_view_count
Please check your logs for more information
怎么解决呀
这里说明一下、我没有跟着老师一样用docker做的、原因是:
1、电脑的内存才8G、要开的软件太多了、 打开虚拟机Ubuntu就占好多内存了
电脑又卡又慢
2、难理解、docker不知道是干嘛的、而且都是命令操作可视化的程度很低对于
我来说很难
所以Mysql、Redis、Solr 都是安装在Win10本机的、跟docker没有沾边...


版本不一样,配置文件也不一样。你这个是int找不到呀。
那你往上找一个类型类似于int的,上面会有的。可以参考别人的嘛。
视频里不是讲解了看别人的嘛。我也是从上面抄的呀。要不我怎么会提供一个资料包给大家呢?就是为了版本统一呀。
买个服务器不香吗?
买个内存条,也不贵。它不香吗,哈哈哈。我原来也是卡,我买了一个之后,那速度真的爽。我同时开虚拟机,idea,webstorm,as都不卡。
<?xml version="1.0" encoding="UTF-8" ?>
<!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<!--
This example schema is the recommended starting point for users.
It should be kept correct and concise, usable out-of-the-box.
For more information, on how to customize this file, please see
http://lucene.apache.org/solr/guide/documents-fields-and-schema-design.html
PERFORMANCE NOTE: this schema includes many optional features and should not
be used for benchmarking. To improve performance one could
- set stored="false" for all fields possible (esp large fields) when you
only need to search on the field but don't need to return the original
value.
- set indexed="false" if you don't need to search on the field, but only
return the field as a result of searching on other indexed fields.
- remove all unneeded copyField statements
- for best index size and searching performance, set "index" to false
for all general text fields, use copyField to copy them to the
catchall "text" field, and use that for searching.
-->
<schema name="default-config" version="1.6">
<!-- attribute "name" is the name of this schema and is only used for display purposes.
version="x.y" is Solr's version number for the schema syntax and
semantics. It should not normally be changed by applications.
1.0: multiValued attribute did not exist, all fields are multiValued
by nature
1.1: multiValued attribute introduced, false by default
1.2: omitTermFreqAndPositions attribute introduced, true by default
except for text fields.
1.3: removed optional field compress feature
1.4: autoGeneratePhraseQueries attribute introduced to drive QueryParser
behavior when a single string produces multiple tokens. Defaults
to off for version >= 1.4
1.5: omitNorms defaults to true for primitive field types
(int, float, boolean, string...)
1.6: useDocValuesAsStored defaults to true.
-->
<!-- Valid attributes for fields:
name: mandatory - the name for the field
type: mandatory - the name of a field type from the
fieldTypes section
indexed: true if this field should be indexed (searchable or sortable)
stored: true if this field should be retrievable
docValues: true if this field should have doc values. Doc Values is
recommended (required, if you are using *Point fields) for faceting,
grouping, sorting and function queries. Doc Values will make the index
faster to load, more NRT-friendly and more memory-efficient.
They are currently only supported by StrField, UUIDField, all
*PointFields, and depending on the field type, they might require
the field to be single-valued, be required or have a default value
(check the documentation of the field type you're interested in for
more information)
multiValued: true if this field may contain multiple values per document
omitNorms: (expert) set to true to omit the norms associated with
this field (this disables length normalization and index-time
boosting for the field, and saves some memory). Only full-text
fields or fields that need an index-time boost need norms.
Norms are omitted for primitive (non-analyzed) types by default.
termVectors: [false] set to true to store the term vector for a
given field.
When using MoreLikeThis, fields used for similarity should be
stored for best performance.
termPositions: Store position information with the term vector.
This will increase storage costs.
termOffsets: Store offset information with the term vector. This
will increase storage costs.
required: The field is required. It will throw an error if the
value does not exist
default: a value that should be used if no value is specified
when adding a document.
-->
<!-- field names should consist of alphanumeric or underscore characters only and
not start with a digit. This is not currently strictly enforced,
but other field names will not have first class support from all components
and back compatibility is not guaranteed. Names with both leading and
trailing underscores (e.g. _version_) are reserved.
-->
<!-- In this _default configset, only four fields are pre-declared:
id, _version_, and _text_ and _root_. All other fields will be type guessed and added via the
"add-unknown-fields-to-the-schema" update request processor chain declared in solrconfig.xml.
Note that many dynamic fields are also defined - you can use them to specify a
field's type via field naming conventions - see below.
WARNING: The _text_ catch-all field will significantly increase your index size.
If you don't need it, consider removing it and the corresponding copyField directive.
-->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- docValues are enabled by default for long type so we don't need to index the version field -->
<field name="_version_" type="plong" indexed="false" stored="false"/>
<!-- If you don't use child/nested documents, then you should remove the next two fields: -->
<!-- for nested documents (minimal; points to root document) -->
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<!-- for nested documents (relationship tracking) -->
<field name="_nest_path_" type="_nest_path_" /><fieldType name="_nest_path_" class="solr.NestPathField" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
<!-- This can be enabled, in case the client does not know what fields may be searched. It isn't enabled by default
because it's very expensive to index everything twice. -->
<!-- <copyField source="*" dest="_text_"/> -->
<!-- Dynamic field definitions allow using convention over configuration
for fields via the specification of patterns to match field names.
EXAMPLE: name="*_i" will match any field ending in _i (like myid_i, z_i)
RESTRICTION: the glob-like pattern in the name attribute must have a "*" only at the start or the end. -->
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>
<dynamicField name="*_is" type="pints" indexed="true" stored="true"/>
<dynamicField name="*_s" type="string" indexed="true" stored="true" />
<dynamicField name="*_ss" type="strings" indexed="true" stored="true"/>
<dynamicField name="*_l" type="plong" indexed="true" stored="true"/>
<dynamicField name="*_ls" type="plongs" indexed="true" stored="true"/>
<dynamicField name="*_t" type="text_general" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_txt" type="text_general" indexed="true" stored="true"/>
<dynamicField name="*_b" type="boolean" indexed="true" stored="true"/>
<dynamicField name="*_bs" type="booleans" indexed="true" stored="true"/>
<dynamicField name="*_f" type="pfloat" indexed="true" stored="true"/>
<dynamicField name="*_fs" type="pfloats" indexed="true" stored="true"/>
<dynamicField name="*_d" type="pdouble" indexed="true" stored="true"/>
<dynamicField name="*_ds" type="pdoubles" indexed="true" stored="true"/>
<dynamicField name="random_*" type="random"/>
<dynamicField name="ignored_*" type="ignored"/>
<!-- Type used for data-driven schema, to add a string copy for each text field -->
<dynamicField name="*_str" type="strings" stored="false" docValues="true" indexed="false" useDocValuesAsStored="false"/>
<dynamicField name="*_dt" type="pdate" indexed="true" stored="true"/>
<dynamicField name="*_dts" type="pdate" indexed="true" stored="true" multiValued="true"/>
<dynamicField name="*_p" type="location" indexed="true" stored="true"/>
<dynamicField name="*_srpt" type="location_rpt" indexed="true" stored="true"/>
<!-- payloaded dynamic fields -->
<dynamicField name="*_dpf" type="delimited_payloads_float" indexed="true" stored="true"/>
<dynamicField name="*_dpi" type="delimited_payloads_int" indexed="true" stored="true"/>
<dynamicField name="*_dps" type="delimited_payloads_string" indexed="true" stored="true"/>
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>
<!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<uniqueKey>id</uniqueKey>
<!-- copyField commands copy one field to another at the time a document
is added to the index. It's used either to index the same field differently,
or to add multiple fields to the same field for easier/faster searching.
<copyField source="sourceFieldName" dest="destinationFieldName"/>
-->
<!-- field type definitions. The "name" attribute is
just a label to be used by field definitions. The "class"
attribute and any other attributes determine the real
behavior of the fieldType.
Class names starting with "solr" refer to java classes in a
standard package such as org.apache.solr.analysis
-->
<!-- sortMissingLast and sortMissingFirst attributes are optional attributes are
currently supported on types that are sorted internally as strings
and on numeric types.
This includes "string", "boolean", "pint", "pfloat", "plong", "pdate", "pdouble".
- If sortMissingLast="true", then a sort on this field will cause documents
without the field to come after documents with the field,
regardless of the requested sort order (asc or desc).
- If sortMissingFirst="true", then a sort on this field will cause documents
without the field to come before documents with the field,
regardless of the requested sort order.
- If sortMissingLast="false" and sortMissingFirst="false" (the default),
then default lucene sorting will be used which places docs without the
field first in an ascending sort and last in a descending sort.
-->
<!-- The StrField type is not analyzed, but indexed/stored verbatim. -->
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="strings" class="solr.StrField" sortMissingLast="true" multiValued="true" docValues="true" />
<!-- boolean type: "true" or "false" -->
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="booleans" class="solr.BoolField" sortMissingLast="true" multiValued="true"/>
<!--
Numeric field types that index values using KD-trees.
Point fields don't support FieldCache, so they must have docValues="true" if needed for sorting, faceting, functions, etc.
-->
<fieldType name="pint" class="solr.IntPointField" docValues="true"/>
<fieldType name="pfloat" class="solr.FloatPointField" docValues="true"/>
<fieldType name="plong" class="solr.LongPointField" docValues="true"/>
<fieldType name="pdouble" class="solr.DoublePointField" docValues="true"/>
<fieldType name="pints" class="solr.IntPointField" docValues="true" multiValued="true"/>
<fieldType name="pfloats" class="solr.FloatPointField" docValues="true" multiValued="true"/>
<fieldType name="plongs" class="solr.LongPointField" docValues="true" multiValued="true"/>
<fieldType name="pdoubles" class="solr.DoublePointField" docValues="true" multiValued="true"/>
<fieldType name="random" class="solr.RandomSortField" indexed="true"/>
<!-- since fields of this type are by default not stored or indexed,
any data added to them will be ignored outright. -->
<fieldType name="ignored" stored="false" indexed="false" multiValued="true" class="solr.StrField" />
<!-- The format for this date field is of the form 1995-12-31T23:59:59Z, and
is a more restricted form of the canonical representation of dateTime
http://www.w3.org/TR/xmlschema-2/#dateTime
The trailing "Z" designates UTC time and is mandatory.
Optional fractional seconds are allowed: 1995-12-31T23:59:59.999Z
All other components are mandatory.
Expressions can also be used to denote calculations that should be
performed relative to "NOW" to determine the value, ie...
NOW/HOUR
... Round to the start of the current hour
NOW-1DAY
... Exactly 1 day prior to now
NOW/DAY+6MONTHS+3DAYS
... 6 months and 3 days in the future from the start of
the current day
-->
<!-- KD-tree versions of date fields -->
<fieldType name="pdate" class="solr.DatePointField" docValues="true"/>
<fieldType name="pdates" class="solr.DatePointField" docValues="true" multiValued="true"/>
<!--Binary data type. The data should be sent/retrieved in as Base64 encoded Strings -->
<fieldType name="binary" class="solr.BinaryField"/>
<!--
RankFields can be used to store scoring factors to improve document ranking. They should be used
in combination with RankQParserPlugin.
(experimental)
-->
<fieldType name="rank" class="solr.RankField"/>
<!-- solr.TextField allows the specification of custom text analyzers
specified as a tokenizer and a list of token filters. Different
analyzers may be specified for indexing and querying.
The optional positionIncrementGap puts space between multiple fields of
this type on the same document, with the purpose of preventing false phrase
matching across fields.
For more info on customizing your analyzer chain, please see
http://lucene.apache.org/solr/guide/understanding-analyzers-tokenizers-and-filters.html#understanding-analyzers-tokenizers-and-filters
-->
<!-- One can also specify an existing Analyzer class that has a
default constructor via the class attribute on the analyzer element.
Example:
<fieldType name="text_greek" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.el.GreekAnalyzer"/>
</fieldType>
-->
<!-- A text field that only splits on whitespace for exact matching of words -->
<dynamicField name="*_ws" type="text_ws" indexed="true" stored="true"/>
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
<!-- A general text field that has reasonable, generic
cross-language defaults: it tokenizes with StandardTokenizer,
removes stop words from case-insensitive "stopwords.txt"
(empty by default), and down cases. At query time only, it
also applies synonyms.
-->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- SortableTextField generaly functions exactly like TextField,
except that it supports, and by default uses, docValues for sorting (or faceting)
on the first 1024 characters of the original field values (which is configurable).
This makes it a bit more useful then TextField in many situations, but the trade-off
is that it takes up more space on disk; which is why it's not used in place of TextField
for every fieldType in this _default schema.
-->
<dynamicField name="*_t_sort" type="text_gen_sort" indexed="true" stored="true" multiValued="false"/>
<dynamicField name="*_txt_sort" type="text_gen_sort" indexed="true" stored="true"/>
<fieldType name="text_gen_sort" class="solr.SortableTextField" positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- A text field with defaults appropriate for English: it tokenizes with StandardTokenizer,
removes English stop words (lang/stopwords_en.txt), down cases, protects words from protwords.txt, and
finally applies Porter's stemming. The query time analyzer also applies synonyms from synonyms.txt. -->
<dynamicField name="*_txt_en" type="text_en" indexed="true" stored="true"/>
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.FlattenGraphFilterFactory"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.EnglishPossessiveFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<!-- Optionally you may want to use this less aggressive stemmer instead of PorterStemFilterFactory:
<filter class="solr.EnglishMinimalStemFilterFactory"/>
-->
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- A text field with defaults appropriate for English, plus
aggressive word-splitting and autophrase features enabled.
This field is just like text_en, except it adds
WordDelimiterGraphFilter to enable splitting and matching of
words on case-change, alpha numeric boundaries, and
non-alphanumeric chars. This means certain compound word
cases will work, for example query "wi fi" will match
document "WiFi" or "wi-fi".
-->
<dynamicField name="*_txt_en_split" type="text_en_splitting" indexed="true" stored="true"/>
<fieldType name="text_en_splitting" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<!-- in this example, we will only use synonyms at query time
<filter class="solr.SynonymGraphFilterFactory" synonyms="index_synonyms.txt" ignoreCase="true" expand="false"/>
-->
<!-- Case insensitive stop word removal.
-->
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="lang/stopwords_en.txt"
/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="1" generateNumberParts="1" catenateWords="0" catenateNumbers="0" catenateAll="0" splitOnCaseChange="1"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.PorterStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Less flexible matching, but less false matches. Probably not ideal for product names,
but may be good for SKUs. Can insert dashes in the wrong place and still match. -->
<dynamicField name="*_txt_en_split_tight" type="text_en_splitting_tight" indexed="true" stored="true"/>
<fieldType name="text_en_splitting_tight" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens that appear at the same position - sometimes
possible with WordDelimiterGraphFilter in conjuncton with stemming. -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
<filter class="solr.FlattenGraphFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="false"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_en.txt"/>
<filter class="solr.WordDelimiterGraphFilterFactory" generateWordParts="0" generateNumberParts="0" catenateWords="1" catenateNumbers="1" catenateAll="0"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeywordMarkerFilterFactory" protected="protwords.txt"/>
<filter class="solr.EnglishMinimalStemFilterFactory"/>
<!-- this filter can remove any duplicate tokens that appear at the same position - sometimes
possible with WordDelimiterGraphFilter in conjuncton with stemming. -->
<filter class="solr.RemoveDuplicatesTokenFilterFactory"/>
</analyzer>
</fieldType>
<!-- Just like text_general except it reverses the characters of
each token, to enable more efficient leading wildcard queries.
-->
<dynamicField name="*_txt_rev" type="text_general_rev" indexed="true" stored="true"/>
<fieldType name="text_general_rev" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ReversedWildcardFilterFactory" withOriginal="true"
maxPosAsterisk="3" maxPosQuestion="2" maxFractionAsterisk="0.33"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<dynamicField name="*_phon_en" type="phonetic_en" indexed="true" stored="true"/>
<fieldType name="phonetic_en" stored="false" indexed="true" class="solr.TextField" >
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.DoubleMetaphoneFilterFactory" inject="false"/>
</analyzer>
</fieldType>
<!-- lowercases the entire field value, keeping it as a single token. -->
<dynamicField name="*_s_lower" type="lowercase" indexed="true" stored="true"/>
<fieldType name="lowercase" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.KeywordTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!--
Example of using PathHierarchyTokenizerFactory at index time, so
queries for paths match documents at that path, or in descendent paths
-->
<dynamicField name="*_descendent_path" type="descendent_path" indexed="true" stored="true"/>
<fieldType name="descendent_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
</fieldType>
<!--
Example of using PathHierarchyTokenizerFactory at query time, so
queries for paths match documents at that path, or in ancestor paths
-->
<dynamicField name="*_ancestor_path" type="ancestor_path" indexed="true" stored="true"/>
<fieldType name="ancestor_path" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.KeywordTokenizerFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.PathHierarchyTokenizerFactory" delimiter="/" />
</analyzer>
</fieldType>
<!-- This point type indexes the coordinates as separate fields (subFields)
If subFieldType is defined, it references a type, and a dynamic field
definition is created matching *___<typename>. Alternately, if
subFieldSuffix is defined, that is used to create the subFields.
Example: if subFieldType="double", then the coordinates would be
indexed in fields myloc_0___double,myloc_1___double.
Example: if subFieldSuffix="_d" then the coordinates would be indexed
in fields myloc_0_d,myloc_1_d
The subFields are an implementation detail of the fieldType, and end
users normally should not need to know about them.
-->
<dynamicField name="*_point" type="point" indexed="true" stored="true"/>
<fieldType name="point" class="solr.PointType" dimension="2" subFieldSuffix="_d"/>
<!-- A specialized field for geospatial search filters and distance sorting. -->
<fieldType name="location" class="solr.LatLonPointSpatialField" docValues="true"/>
<!-- A geospatial field type that supports multiValued and polygon shapes.
For more information about this and other spatial fields see:
http://lucene.apache.org/solr/guide/spatial-search.html
-->
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025" maxDistErr="0.001" distanceUnits="kilometers" />
<!-- Payloaded field types -->
<fieldType name="delimited_payloads_float" stored="false" indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="float"/>
</analyzer>
</fieldType>
<fieldType name="delimited_payloads_int" stored="false" indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="integer"/>
</analyzer>
</fieldType>
<fieldType name="delimited_payloads_string" stored="false" indexed="true" class="solr.TextField">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
<filter class="solr.DelimitedPayloadTokenFilterFactory" encoder="identity"/>
</analyzer>
</fieldType>
<!-- some examples for different languages (generally ordered by ISO code) -->
<!-- Arabic -->
<dynamicField name="*_txt_ar" type="text_ar" indexed="true" stored="true"/>
<fieldType name="text_ar" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- for any non-arabic -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ar.txt" />
<!-- normalizes ﻯ to ﻱ, etc -->
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.ArabicStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Bulgarian -->
<dynamicField name="*_txt_bg" type="text_bg" indexed="true" stored="true"/>
<fieldType name="text_bg" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_bg.txt" />
<filter class="solr.BulgarianStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Catalan -->
<dynamicField name="*_txt_ca" type="text_ca" indexed="true" stored="true"/>
<fieldType name="text_ca" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_ca.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ca.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Catalan"/>
</analyzer>
</fieldType>
<!-- CJK bigram (see text_ja for a Japanese configuration using morphological analysis) -->
<dynamicField name="*_txt_cjk" type="text_cjk" indexed="true" stored="true"/>
<fieldType name="text_cjk" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- normalize width before bigram, as e.g. half-width dakuten combine -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- for any non-CJK -->
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.CJKBigramFilterFactory"/>
</analyzer>
</fieldType>
<!-- Czech -->
<dynamicField name="*_txt_cz" type="text_cz" indexed="true" stored="true"/>
<fieldType name="text_cz" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_cz.txt" />
<filter class="solr.CzechStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Danish -->
<dynamicField name="*_txt_da" type="text_da" indexed="true" stored="true"/>
<fieldType name="text_da" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_da.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Danish"/>
</analyzer>
</fieldType>
<!-- German -->
<dynamicField name="*_txt_de" type="text_de" indexed="true" stored="true"/>
<fieldType name="text_de" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_de.txt" format="snowball" />
<filter class="solr.GermanNormalizationFilterFactory"/>
<filter class="solr.GermanLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.GermanMinimalStemFilterFactory"/> -->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory" language="German2"/> -->
</analyzer>
</fieldType>
<!-- Greek -->
<dynamicField name="*_txt_el" type="text_el" indexed="true" stored="true"/>
<fieldType name="text_el" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- greek specific lowercase for sigma -->
<filter class="solr.GreekLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="false" words="lang/stopwords_el.txt" />
<filter class="solr.GreekStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Spanish -->
<dynamicField name="*_txt_es" type="text_es" indexed="true" stored="true"/>
<fieldType name="text_es" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_es.txt" format="snowball" />
<filter class="solr.SpanishLightStemFilterFactory"/>
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory" language="Spanish"/> -->
</analyzer>
</fieldType>
<!-- Estonian -->
<dynamicField name="*_txt_et" type="text_et" indexed="true" stored="true"/>
<fieldType name="text_et" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_et.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Estonian"/>
</analyzer>
</fieldType>
<!-- Basque -->
<dynamicField name="*_txt_eu" type="text_eu" indexed="true" stored="true"/>
<fieldType name="text_eu" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_eu.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Basque"/>
</analyzer>
</fieldType>
<!-- Persian -->
<dynamicField name="*_txt_fa" type="text_fa" indexed="true" stored="true"/>
<fieldType name="text_fa" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<!-- for ZWNJ -->
<charFilter class="solr.PersianCharFilterFactory"/>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.ArabicNormalizationFilterFactory"/>
<filter class="solr.PersianNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fa.txt" />
</analyzer>
</fieldType>
<!-- Finnish -->
<dynamicField name="*_txt_fi" type="text_fi" indexed="true" stored="true"/>
<fieldType name="text_fi" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fi.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Finnish"/>
<!-- less aggressive: <filter class="solr.FinnishLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- French -->
<dynamicField name="*_txt_fr" type="text_fr" indexed="true" stored="true"/>
<fieldType name="text_fr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_fr.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_fr.txt" format="snowball" />
<filter class="solr.FrenchLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.FrenchMinimalStemFilterFactory"/> -->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory" language="French"/> -->
</analyzer>
</fieldType>
<!-- Irish -->
<dynamicField name="*_txt_ga" type="text_ga" indexed="true" stored="true"/>
<fieldType name="text_ga" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes d', etc -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_ga.txt"/>
<!-- removes n-, etc. position increments is intentionally false! -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/hyphenations_ga.txt"/>
<filter class="solr.IrishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ga.txt"/>
<filter class="solr.SnowballPorterFilterFactory" language="Irish"/>
</analyzer>
</fieldType>
<!-- Galician -->
<dynamicField name="*_txt_gl" type="text_gl" indexed="true" stored="true"/>
<fieldType name="text_gl" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_gl.txt" />
<filter class="solr.GalicianStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.GalicianMinimalStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- Hindi -->
<dynamicField name="*_txt_hi" type="text_hi" indexed="true" stored="true"/>
<fieldType name="text_hi" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<!-- normalizes unicode representation -->
<filter class="solr.IndicNormalizationFilterFactory"/>
<!-- normalizes variation in spelling -->
<filter class="solr.HindiNormalizationFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_hi.txt" />
<filter class="solr.HindiStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Hungarian -->
<dynamicField name="*_txt_hu" type="text_hu" indexed="true" stored="true"/>
<fieldType name="text_hu" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_hu.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Hungarian"/>
<!-- less aggressive: <filter class="solr.HungarianLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- Armenian -->
<dynamicField name="*_txt_hy" type="text_hy" indexed="true" stored="true"/>
<fieldType name="text_hy" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_hy.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Armenian"/>
</analyzer>
</fieldType>
<!-- Indonesian -->
<dynamicField name="*_txt_id" type="text_id" indexed="true" stored="true"/>
<fieldType name="text_id" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_id.txt" />
<!-- for a less aggressive approach (only inflectional suffixes), set stemDerivational to false -->
<filter class="solr.IndonesianStemFilterFactory" stemDerivational="true"/>
</analyzer>
</fieldType>
<!-- Italian -->
<dynamicField name="*_txt_it" type="text_it" indexed="true" stored="true"/>
<fieldType name="text_it" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<!-- removes l', etc -->
<filter class="solr.ElisionFilterFactory" ignoreCase="true" articles="lang/contractions_it.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_it.txt" format="snowball" />
<filter class="solr.ItalianLightStemFilterFactory"/>
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory" language="Italian"/> -->
</analyzer>
</fieldType>
<!-- Japanese using morphological analysis (see text_cjk for a configuration using bigramming)
NOTE: If you want to optimize search for precision, use default operator AND in your request
handler config (q.op) Use OR if you would like to optimize for recall (default).
-->
<dynamicField name="*_txt_ja" type="text_ja" indexed="true" stored="true"/>
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<!-- Kuromoji Japanese morphological analyzer/tokenizer (JapaneseTokenizer)
Kuromoji has a search mode (default) that does segmentation useful for search. A heuristic
is used to segment compounds into its parts and the compound itself is kept as synonym.
Valid values for attribute mode are:
normal: regular segmentation
search: segmentation useful for search with synonyms compounds (default)
extended: same as search mode, but unigrams unknown words (experimental)
For some applications it might be good to use search mode for indexing and normal mode for
queries to reduce recall and prevent parts of compounds from being matched and highlighted.
Use <analyzer type="index"> and <analyzer type="query"> for this and mode normal in query.
Kuromoji also has a convenient user dictionary feature that allows overriding the statistical
model with your own entries for segmentation, part-of-speech tags and readings without a need
to specify weights. Notice that user dictionaries have not been subject to extensive testing.
User dictionary attributes are:
userDictionary: user dictionary filename
userDictionaryEncoding: user dictionary encoding (default is UTF-8)
See lang/userdict_ja.txt for a sample user dictionary file.
Punctuation characters are discarded by default. Use discardPunctuation="false" to keep them.
-->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<!--<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>-->
<!-- Reduces inflected verbs and adjectives to their base/dictionary forms (辞書形) -->
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<!-- Removes tokens with certain part-of-speech tags -->
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt" />
<!-- Normalizes full-width romaji to half-width and half-width kana to full-width (Unicode NFKC subset) -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- Removes common tokens typically not useful for search, but have a negative effect on ranking -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt" />
<!-- Normalizes common katakana spelling variations by removing any last long sound character (U+30FC) -->
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<!-- Lower-cases romaji characters -->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<!-- Korean morphological analysis -->
<dynamicField name="*_txt_ko" type="text_ko" indexed="true" stored="true"/>
<fieldType name="text_ko" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<!-- Nori Korean morphological analyzer/tokenizer (KoreanTokenizer)
The Korean (nori) analyzer integrates Lucene nori analysis module into Solr.
It uses the mecab-ko-dic dictionary to perform morphological analysis of Korean texts.
This dictionary was built with MeCab, it defines a format for the features adapted
for the Korean language.
Nori also has a convenient user dictionary feature that allows overriding the statistical
model with your own entries for segmentation, part-of-speech tags and readings without a need
to specify weights. Notice that user dictionaries have not been subject to extensive testing.
The tokenizer supports multiple schema attributes:
* userDictionary: User dictionary path.
* userDictionaryEncoding: User dictionary encoding.
* decompoundMode: Decompound mode. Either 'none', 'discard', 'mixed'. Default is 'discard'.
* outputUnknownUnigrams: If true outputs unigrams for unknown words.
-->
<tokenizer class="solr.KoreanTokenizerFactory" decompoundMode="discard" outputUnknownUnigrams="false"/>
<!-- Removes some part of speech stuff like EOMI (Pos.E), you can add a parameter 'tags',
listing the tags to remove. By default it removes:
E, IC, J, MAG, MAJ, MM, SP, SSC, SSO, SC, SE, XPN, XSA, XSN, XSV, UNA, NA, VSV
This is basically an equivalent to stemming.
-->
<filter class="solr.KoreanPartOfSpeechStopFilterFactory" />
<!-- Replaces term text with the Hangul transcription of Hanja characters, if applicable: -->
<filter class="solr.KoreanReadingFormFilterFactory" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>
<!-- Latvian -->
<dynamicField name="*_txt_lv" type="text_lv" indexed="true" stored="true"/>
<fieldType name="text_lv" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_lv.txt" />
<filter class="solr.LatvianStemFilterFactory"/>
</analyzer>
</fieldType>
<!-- Dutch -->
<dynamicField name="*_txt_nl" type="text_nl" indexed="true" stored="true"/>
<fieldType name="text_nl" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_nl.txt" format="snowball" />
<filter class="solr.StemmerOverrideFilterFactory" dictionary="lang/stemdict_nl.txt" ignoreCase="false"/>
<filter class="solr.SnowballPorterFilterFactory" language="Dutch"/>
</analyzer>
</fieldType>
<!-- Norwegian -->
<dynamicField name="*_txt_no" type="text_no" indexed="true" stored="true"/>
<fieldType name="text_no" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_no.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Norwegian"/>
<!-- less aggressive: <filter class="solr.NorwegianLightStemFilterFactory"/> -->
<!-- singular/plural: <filter class="solr.NorwegianMinimalStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- Portuguese -->
<dynamicField name="*_txt_pt" type="text_pt" indexed="true" stored="true"/>
<fieldType name="text_pt" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_pt.txt" format="snowball" />
<filter class="solr.PortugueseLightStemFilterFactory"/>
<!-- less aggressive: <filter class="solr.PortugueseMinimalStemFilterFactory"/> -->
<!-- more aggressive: <filter class="solr.SnowballPorterFilterFactory" language="Portuguese"/> -->
<!-- most aggressive: <filter class="solr.PortugueseStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- Romanian -->
<dynamicField name="*_txt_ro" type="text_ro" indexed="true" stored="true"/>
<fieldType name="text_ro" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ro.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Romanian"/>
</analyzer>
</fieldType>
<!-- Russian -->
<dynamicField name="*_txt_ru" type="text_ru" indexed="true" stored="true"/>
<fieldType name="text_ru" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ru.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Russian"/>
<!-- less aggressive: <filter class="solr.RussianLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- Swedish -->
<dynamicField name="*_txt_sv" type="text_sv" indexed="true" stored="true"/>
<fieldType name="text_sv" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_sv.txt" format="snowball" />
<filter class="solr.SnowballPorterFilterFactory" language="Swedish"/>
<!-- less aggressive: <filter class="solr.SwedishLightStemFilterFactory"/> -->
</analyzer>
</fieldType>
<!-- Thai -->
<dynamicField name="*_txt_th" type="text_th" indexed="true" stored="true"/>
<fieldType name="text_th" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.ThaiTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_th.txt" />
</analyzer>
</fieldType>
<!-- Turkish -->
<dynamicField name="*_txt_tr" type="text_tr" indexed="true" stored="true"/>
<fieldType name="text_tr" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.TurkishLowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="false" words="lang/stopwords_tr.txt" />
<filter class="solr.SnowballPorterFilterFactory" language="Turkish"/>
</analyzer>
</fieldType>
<!-- Similarity is the scoring routine for each document vs. a query.
A custom Similarity or SimilarityFactory may be specified here, but
the default is fine for most applications.
For more info: http://lucene.apache.org/solr/guide/other-schema-elements.html#OtherSchemaElements-Similarity
-->
<!--
<similarity class="com.example.solr.CustomSimilarityFactory">
<str name="paramkey">param value</str>
</similarity>
-->
<!-- 配置smartcn分词器 -->
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
<!--自定义字段,类似于设计数据表一样-->
<!--ID-->
<!--ID 已经在前面有了-->
<!--浏览量-->
<field name="blog_view_count" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--标题-->
<field name="blog_title" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--内容-->
<field name="blog_content" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--创建时间-->
<field name="blog_create_time" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--标签-->
<field name="blog_labels" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--文章链接-->
<field name="blog_url" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--分类ID-->
<field name="blog_category_id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!--搜索item-->
<field name="search_item" type="text_ik" indexed="true" stored="true" required="true" multiValued="true" />
<copyField source="blog_title" dest="search_item"/>
<copyField source="blog_content" dest="search_item"/>
<copyField source="blog_labels" dest="search_item"/>
</schema>