wkhtmltopdf 是一款可以将 HTML 转成 PDF 文件的工具
我通过Java代码去中执行操作处理
使用命令如下、得到如下图的 PDF 文件:
wkhtmltopdf https://baike.baidu.com/item/%E5%8F%B0%E6%B9%BE/122340 e:/abc/baidu.pdf
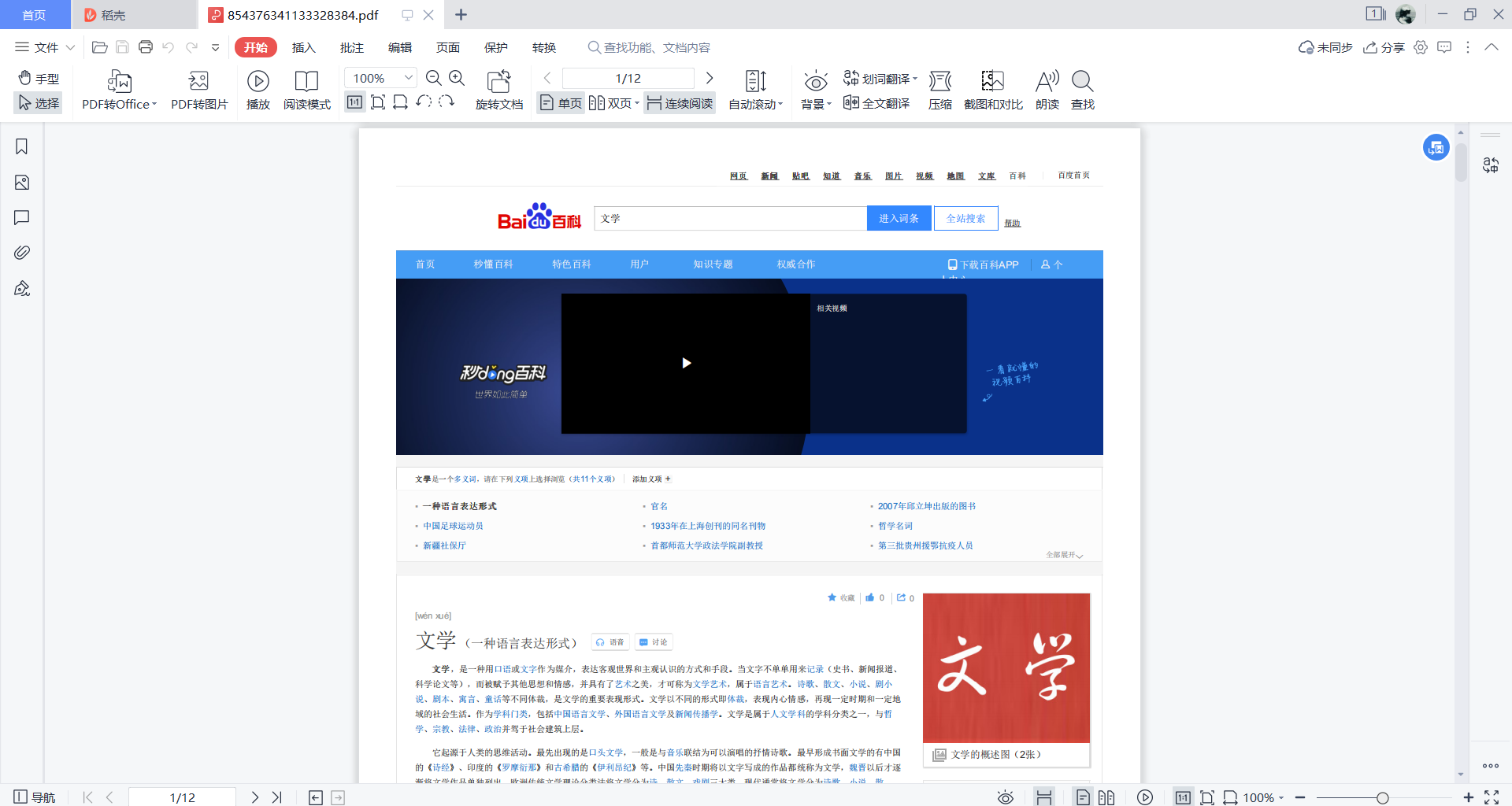
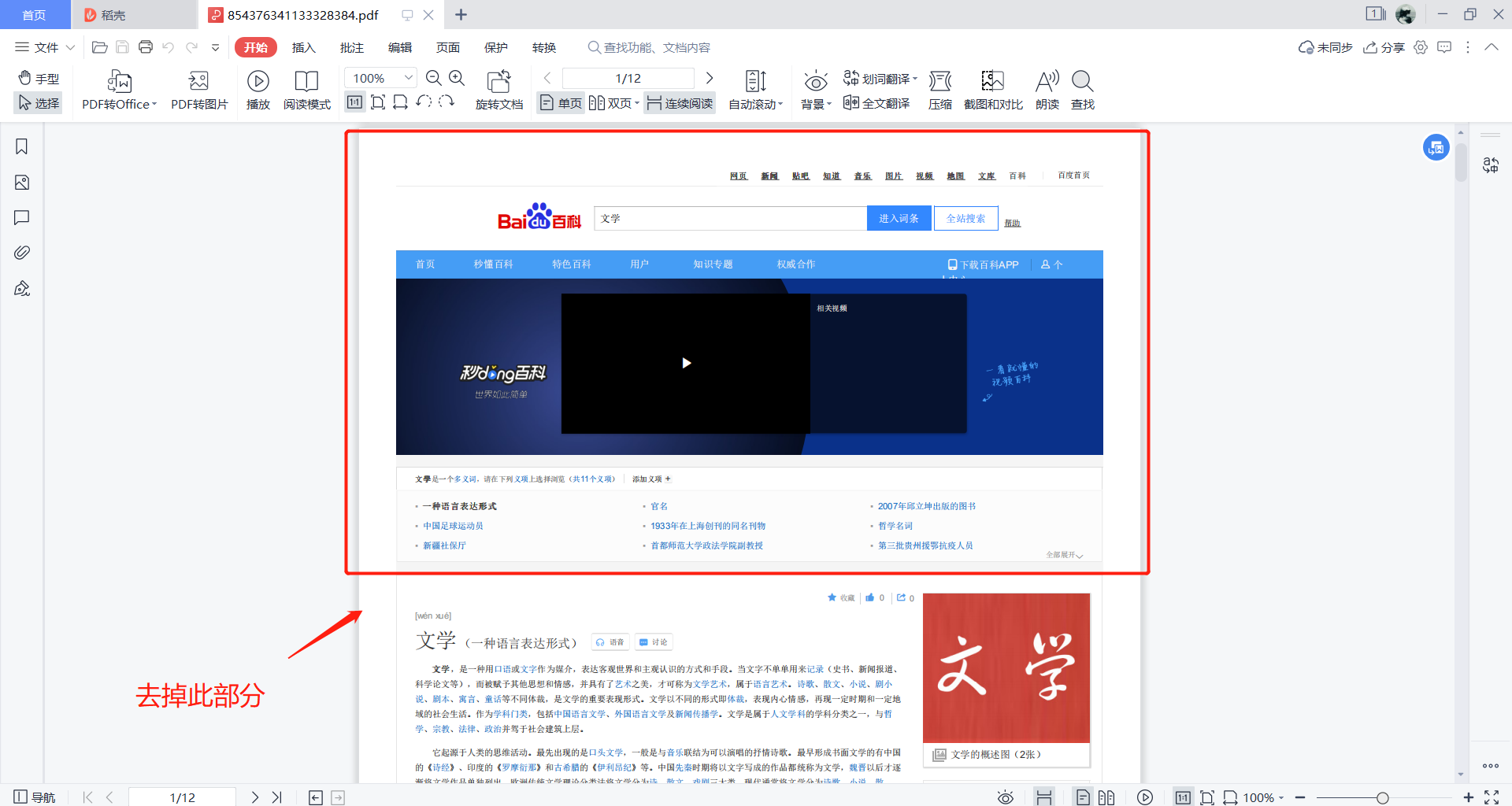
现在有个问题就是我想去掉 百度百科的头部搜索栏元素信息:
wkhtmltopdf https://baike.baidu.com/item/%E5%8F%B0%E6%B9%BE/122340 e:/abc/baidu.pdf
因为使用如上命令必定会有 头部搜索框的元素信息 转 PDF 也避免不了也会有
我尝试了一个办法:
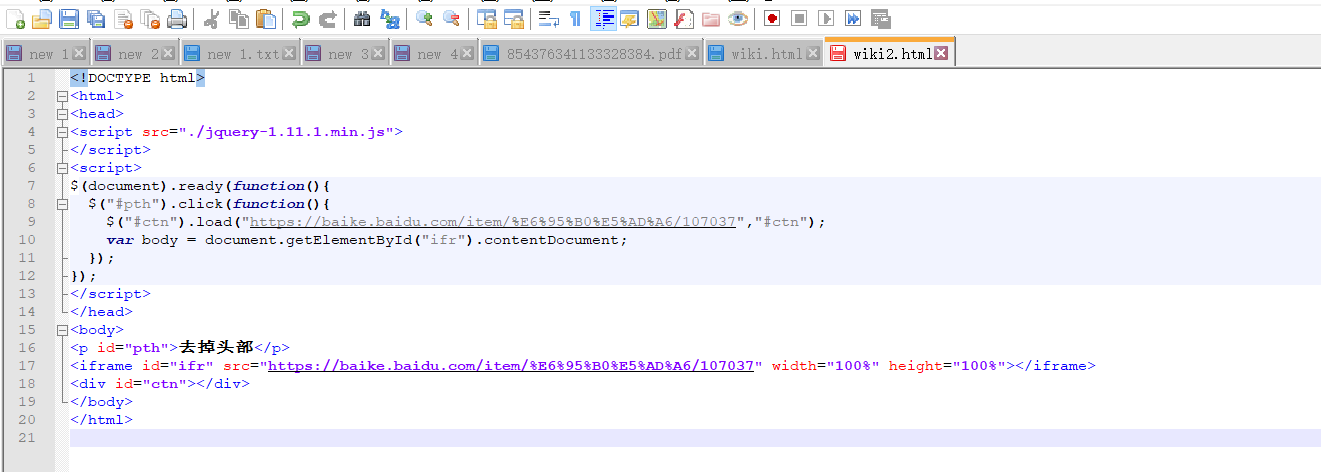
在我本地写一个静态的 HTML 页面 将要转 PDF 的 HTML 页面 、写进一个 iframe 之中去
用 JS 去 remove 掉一些关于 搜索框元素的 div 再转 PDF
可是行不通、原因是 JS 去操作 iframe 中的标签 会出现跨域的问题 、如图:

在 wkhtmltopdf 转 PDF 这里我是没办法解决了
现在想着能不能从 PDF 入手、去试图改变 PDF 里的内容 去掉搜索框标签
小伙伴们 有什么好办法、好点子呢


跨域问题,可以用代理的方式解决。
打算放弃前端跨域去处理dom元素、选择使用 pdfbox 将 pdf 第一页取出后转图片定位裁剪重新覆盖掉 pdf 得首页即可