前些天突然想学一下 solr 、拉大锯老师的课程中关于 solr 的教学我翻不到了,那我就索性去学 es 算了,然后在学习的过程中有一些问题让人很疑惑,我没有 solr 基础,es 也是这两天刚学 、搞得我脑壳疼
es / kibana 版本均为:7.6.1
这里我直接贴上代码:
# 创建库
put lw177777
{
"mappings":{
"properties":{
"name":{
"type":"keyword"
},
"desc":{
"type":"text"
}
}
}
}
# 插入数据
POST /lw177777/_doc/1
{
"name":"我是wzf",
"desc":"wzf_Java"
}
# 获取数据
get /lw177777/_search
{
"query":{
"match":{
"desc":"wzf"
}
}
}
然后就有了如下问题 、我很疑惑为什么会搜不到 、 desc 字段类型是 text :
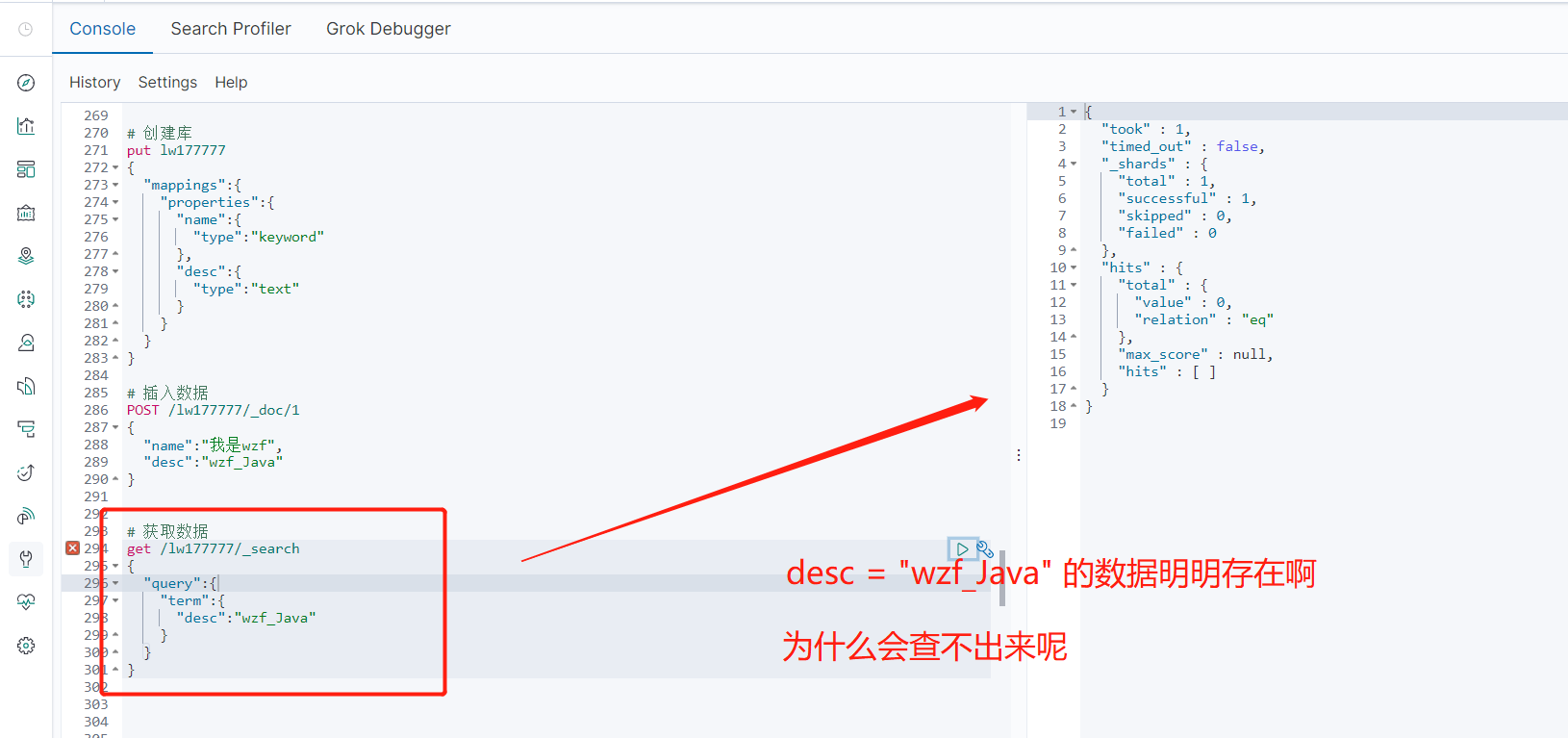
然后我把 term 换成 match 、其他代码不动就能查出来了 :
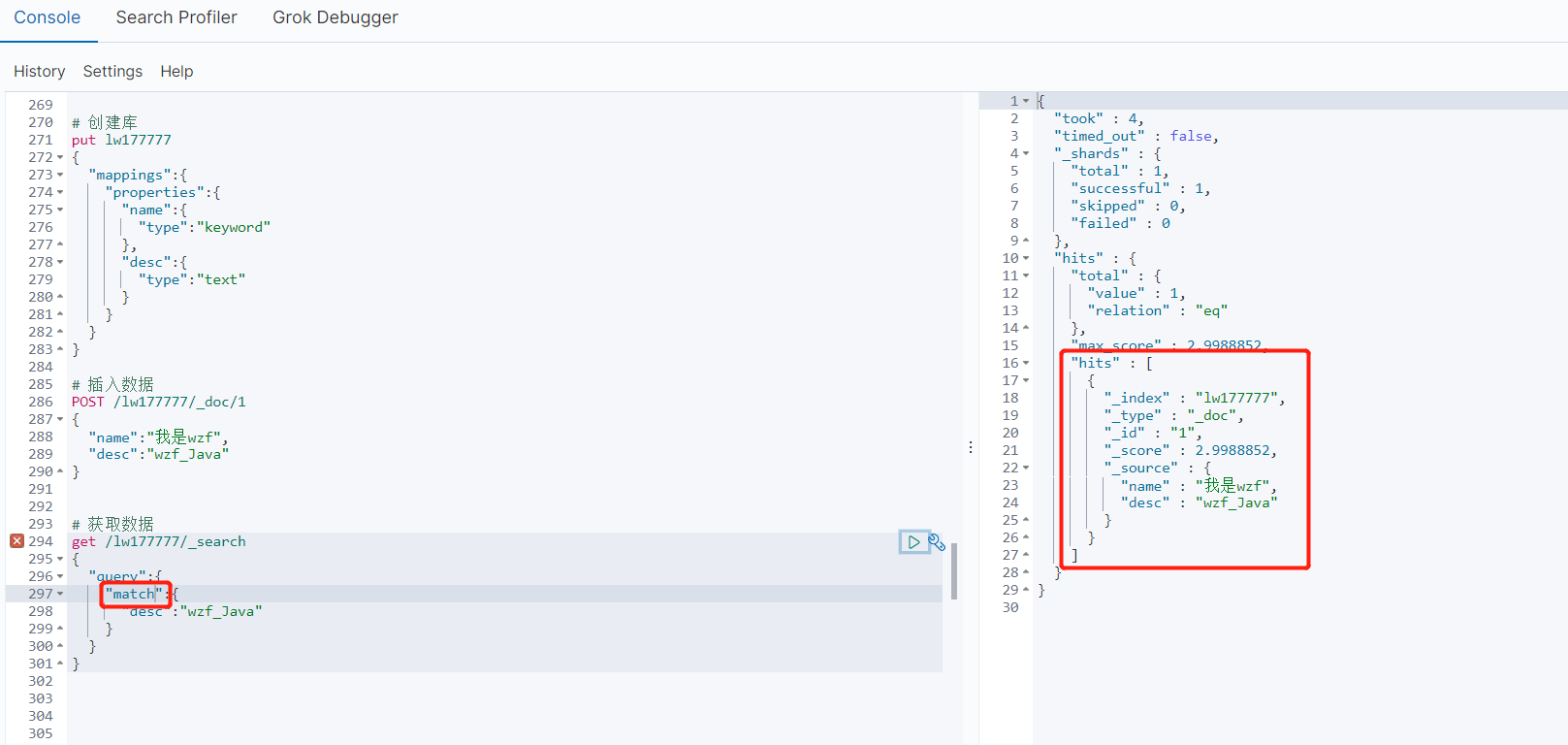
term 是精准匹配 那我传的 "wzf_Java" 这个值、是库里有的啊,咋会搜不出来呢
match 倒可以搜出来,我 tm 直接疑惑
match 去查 "wzf" 也查不出来了
咋不像 SQL 一样呢 如:
select * from lw1777 where desc like '%wzf%'
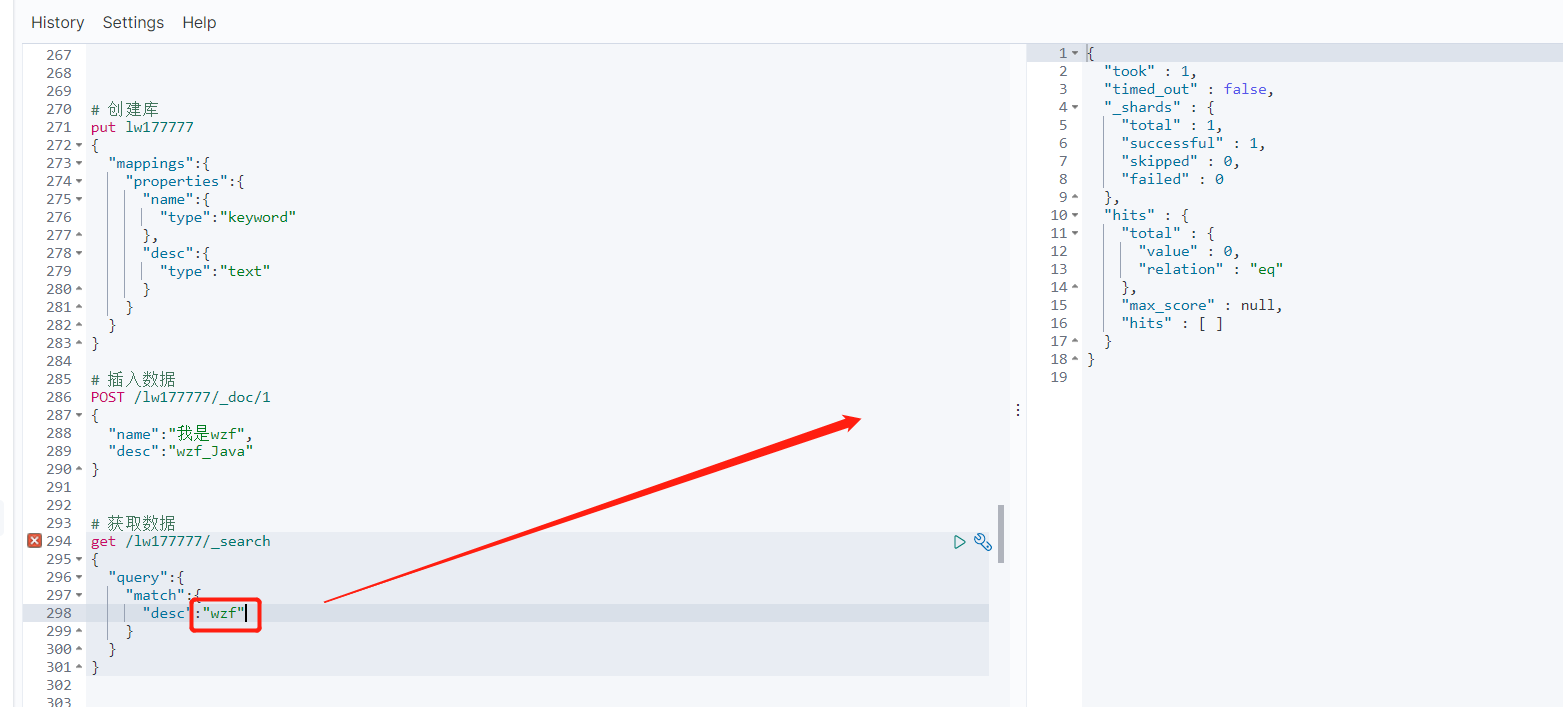
es 这个查询是基于 "ik分词器" 去进行分词检索的嘛 ?
自己组的单词虽然字段值有 ,但是分词库里没有还是照样查不出来
不像 mysql 一样可以模糊搜索 、感觉好难用啊!!
同学们是怎么理解这些的呢? 里面的逻辑是啥呀


为什么是“不应该是想SQL一样嘛”[捂脸]
你果你只为了使用,去github找个demo看看就用上了。用API不难的,拼接查询条件,对内容进行高亮。这是查询。数据入库可以使用logstash.
如果你是学习,去B大找一个看看。