全部 文章 问答 分享 共找到8个相关内容

[文章] Python 网络爬虫练手
Python网络爬虫实战最近在学python,不知不觉把python基础学完了。怎么不搞一个小项目练习一下手呢?所以写一个小的demo练习一下手。这个demo很多不足的地方,后文在表述。
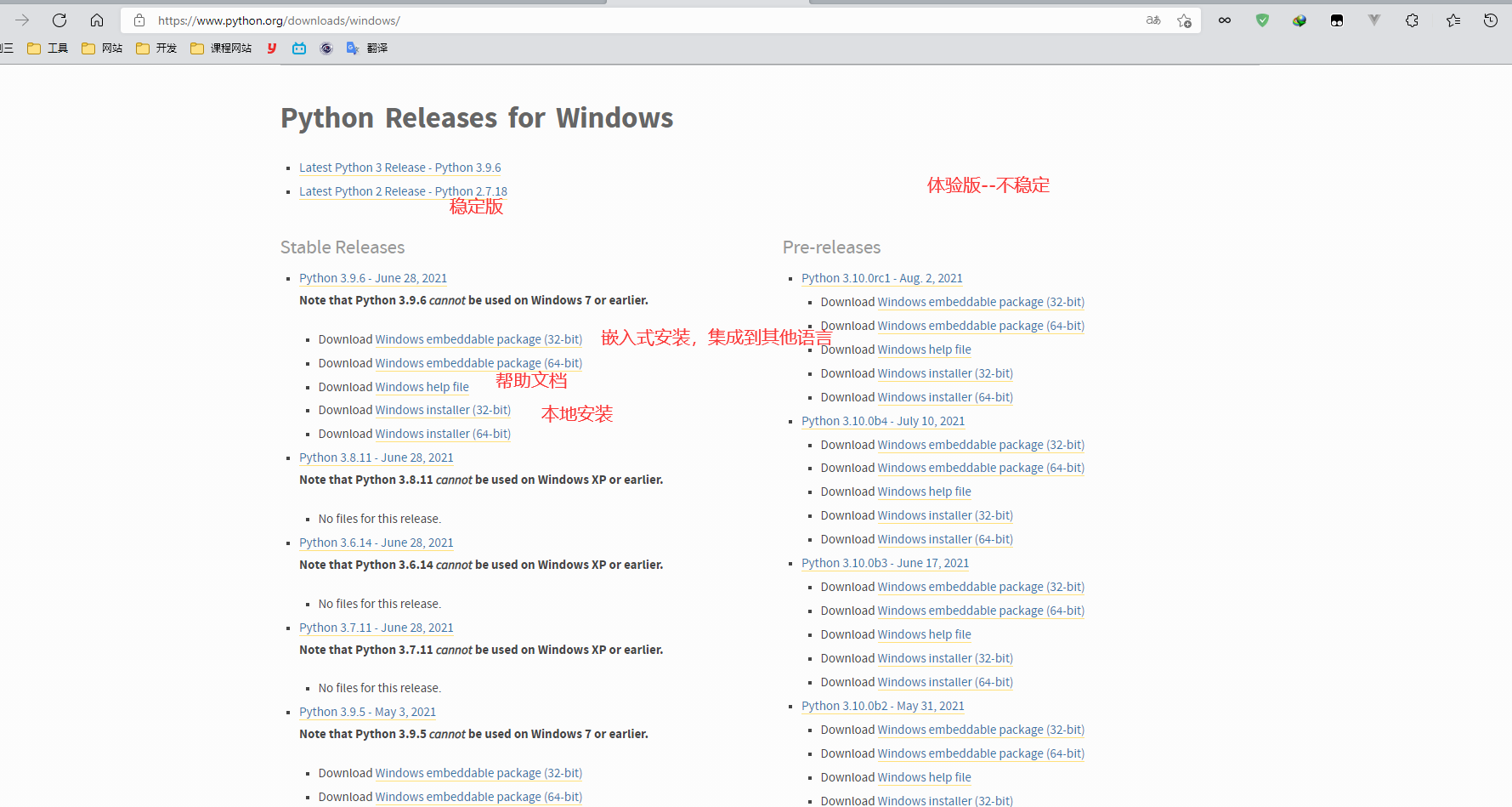
[文章] 学习笔记-Python
:抓取网站中需要的数据核心:爬取网页:爬取整个网页,包含网页中所有的内容解析数据:将网页中得到的数据进行解析难点:爬虫与反爬虫之间博弈用途:数据分析、人工数据集社交软件冷启动舆情监控竞争对手监控相关库:

[文章] B站爬虫如何尽可能加大覆盖面?
起因看到一个网站,可以查到b站用户的历史评论,最早可以造到2015年。试了几个uid都能查到。开始好奇,它是如何实现这么大范围的抓取的?和aicu的大佬聊了一下,得到了一些思路。目标输入用户id,展示用户至今为止发出的评论抓取难点没有这样的接口b站是没有这样通过uid跨视频查询所有评论的接口的,至今也没有被人发现存在这样的接口。我想b站应该也不需要设计出这样的接口给客户端使用。那么,想要知道这个用户的发言,理论上,就要遍历所有b站的视频,把所有评论都抓取。假设,我们先不考虑抓取难度,风控、存储等原因,就是笨办法直接抓,现在出现了第二个问题怎么拿到全站的所有视频?平常我们使用b站,要么个性化推荐,要么自己搜索,要么排行榜。用上面这些方式去找,必然有漏网之鱼。不可能覆盖全部。(以前b站还有分区,也许说可以根据分区接口去遍历所有分区的视频,目前可能已经失效了。)解决思路我们不要直接找视频,我们先找人。找到了人,我就可以找到这个人发的视频。就可以找到视频下的评论。因为b站的所有视频都有一个up主,也就是视频创作者。找到这个视频主之后,那他的粉丝以及关注者,以及这些视频下的评论的用户。又得到一批新的用户id。拿到这些id,重复上述流程。相当于一个图的遍历。这样就可以最大范围的找到大部分用户,从而拿到大部分视频,从而可以拿到大部分的评论。起始的用户id作为遍历的开始,我们直接选择粉丝量大的up主,直接拿百大列表即可。

[文章] 水一篇:尝试用分布式跑密码字典
那么针对单个网站,我们其实可以对响应进行去重,具体的日志只记录响应的id由于数据量较大,可以在本地做一层缓存,定时同步,找不到该响应,再向数据库发起请求可以参考现有开源分布式爬虫进行改造结尾没了

[文章] 开始学习Python的第一天
Python的应用领域目前Python在Web应用后端开发、云基础设施建设、DevOps、网络数据采集(爬虫)、自动化测试、数据分析、机器学习等领域都有着广泛的应用。
1970-01-01 00:00
·
python
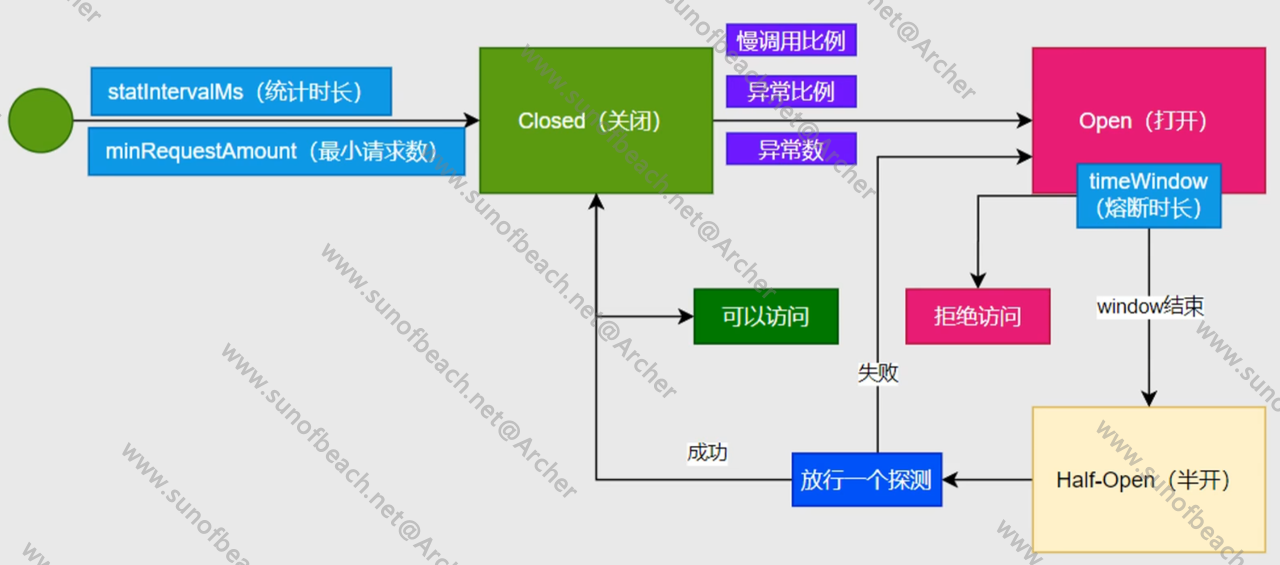
[文章] spring cloud 快速开始 之 sentinel篇
SphUAPI声明式接口:@SentinelResource规则:流量控制:比如每一秒钟能够接收多少的请求熔断降级:防止雪崩的系统保护:根据CPU,RAM等的繁忙都来源访问控制:可以避免同一个IP地址来爬虫热点参数
