Python 网络爬虫实战
最近在学python,不知不觉把python基础学完了。怎么不搞一个小项目练习一下手呢?所以写一个小的demo练习一下手。这个demo很多不足的地方,后文在表述。
http://www.rrdyw.cc/movie/
这是真是看电影的好地方。不需要会员还看高清的但是需要百度网盘。上面分享都是百度网盘的电影链接。我就想把它百度云链接爬下来。
找到网址链接的规律
这个网址显示电影的url 
电影链接是这样的 
page的分类 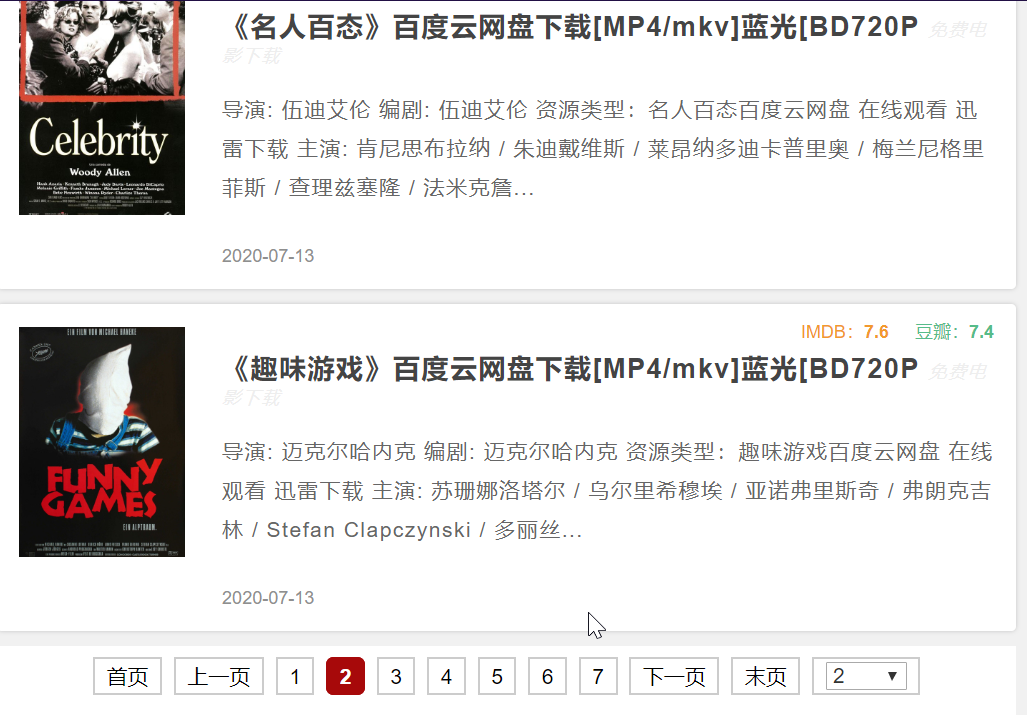 用chrome浏览器 按F12 找到控件的样式 我们只需要找到 下一页这个控件
用chrome浏览器 按F12 找到控件的样式 我们只需要找到 下一页这个控件 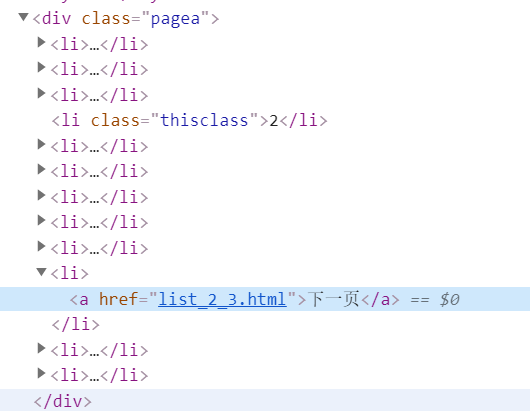
用xpath工具获取下一页的href,我看了是-2个
# 解析网页源代码,获取下一页链接
def parse4link(html, base_url):
link = None
html_elem = etree.HTML(html)
url = html_elem.xpath('//div[@class="pagea"]/li/a/@href')
if url:
link = base_url + url[-2]
return link
获取了下一页的link了,然后就简单了 依次遍历下一页的内容就可以比如
任意一页 http://www.rrdyw.cc/movie/list_2_148.html
和上面一样我们需要获取每一个Item的电影的电影名称,图片地址,电影简介,电影详情链接。方法也和上面相同。
# 解析网页源代码,获取数据
def parse4data(html):
# print(html)
html = etree.HTML(html)
# 电影的名称
title = html.xpath('//div[@class="intro"]/h2/a/@title')
# 电影的图片地址
imageurl = html.xpath('//img[@class="pure-img"]/@data-original')
# 电影简介
brief = html.xpath('//div[@class="brief"]/text()')
# 电影详情页链接
movielink = html.xpath('//div[@class="intro"]/h2/a/@href')
# 获取百度的链接的和提取code
baiduurl, getcode = getBaidulink(movielink)
data = zip(title, imageurl, brief, movielink,baiduurl, getcode)
return data
得到电影的详情链接之后就需要找这个电影的百度云盘地址和提取码了
比如变形金刚5这个电影
http://www.rrdyw.cc/movie/2019/0203/2493.html

用chrome 提取网页的标签,调用xpath识别
,
# 获取link的电影的百度链接和提取码
def getBaidulink(links):
base_url = 'http://www.rrdyw.cc'
urls = list()
codes = list()
for link in links:
print("%s 爬取内容" + link)
link = base_url + link
html = get_page(link)
html_elem = etree.HTML(html)
urllist = html_elem.xpath('//div[@class="movie-des shadow"]/div[@class="movie-txt"]/span/a/@href')
url = getbaiduyunUrl(urllist)
getcodelist = html_elem.xpath('//div[@class="movie-txt"]/span/text()')
getcode = getbaiduyuncode(getcodelist)
urls.append(url)
codes.append(getcode)
return urls, codes
这样的电影的链接就找到了。我们只需要包存到本地就可以。想看你要的电影了。 完整的code代码
import requests
from lxml import etree
import re
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding="utf-8"
html = response.text
return html
# 解析网页源代码,获取下一页链接
def parse4link(html, base_url):
link = None
html_elem = etree.HTML(html)
url = html_elem.xpath('//div[@class="pagea"]/li/a/@href')
if url:
link = base_url + url[-2]
return link
# 解析获取的list
def getbaiduyunUrl(urllist):
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+') # 匹配模式
for li in urllist:
url = re.findall(pattern, str(li))
if len(url) > 0:
# print(url)
return url
# 获取提取码
def getbaiduyuncode(getcodelist):
pattern = re.compile(r'提取码: [a-zA-Z0-9][a-zA-Z0-9][a-zA-Z0-9][a-zA-Z0-9]')
for li in getcodelist:
url = re.findall(pattern, str(li))
if len(url) > 0:
return url
# 获取link的电影的百度链接和提取码
def getBaidulink(links):
base_url = 'http://www.rrdyw.cc'
urls = list()
codes = list()
for link in links:
print("%s 爬取内容" + link)
link = base_url + link
html = get_page(link)
html_elem = etree.HTML(html)
urllist = html_elem.xpath('//div[@class="movie-des shadow"]/div[@class="movie-txt"]/span/a/@href')
url = getbaiduyunUrl(urllist)
getcodelist = html_elem.xpath('//div[@class="movie-txt"]/span/text()')
getcode = getbaiduyuncode(getcodelist)
urls.append(url)
codes.append(getcode)
return urls, codes
# 解析网页源代码,获取数据
def parse4data(html):
# print(html)
html = etree.HTML(html)
# 电影的名称
title = html.xpath('//div[@class="intro"]/h2/a/@title')
# 电影的图片地址
imageurl = html.xpath('//img[@class="pure-img"]/@data-original')
# 电影简介
brief = html.xpath('//div[@class="brief"]/text()')
# 电影详情页链接
movielink = html.xpath('//div[@class="intro"]/h2/a/@href')
# 获取百度的链接的和提取code
baiduurl, getcode = getBaidulink(movielink)
data = zip(title, imageurl, brief, movielink,baiduurl, getcode)
return data
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('movie.txt', 'w', encoding='utf-8')
elif fm == 'json':
fd = open('movie.json', 'w', encoding='utf-8')
elif fm == 'csv':
fd = open('movie.csv', 'w', encoding='utf-8', newline='')
return fd
# 将数据保存到文件
def save2file(fm, fd, data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('title:' + str(item[0]) + '\n')
fd.write('imageurl:' + str(item[1]) + '\n')
fd.write('brief:' + str(item[2]) + '\n')
fd.write('movielink:' + str(item[3]) + '\n')
fd.write('baiduurl:' + str(item[4]) + '\n')
fd.write('baiducode:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('title', 'imageurl', 'brief', 'movielink')
for item in data:
json.dump(dict(zip(temp, item)), fd, ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def getmovie():
base_url = 'http://www.rrdyw.cc/movie/'
fm = "txt"
fd = openfile("txt")
print('开始爬取')
link = base_url
while link:
print('正在爬取 ' + str(link) + ' ......')
html = get_page(link)
link = parse4link(html, base_url)
data = parse4data(html)
save2file(fm, fd, data)
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
getmovie()
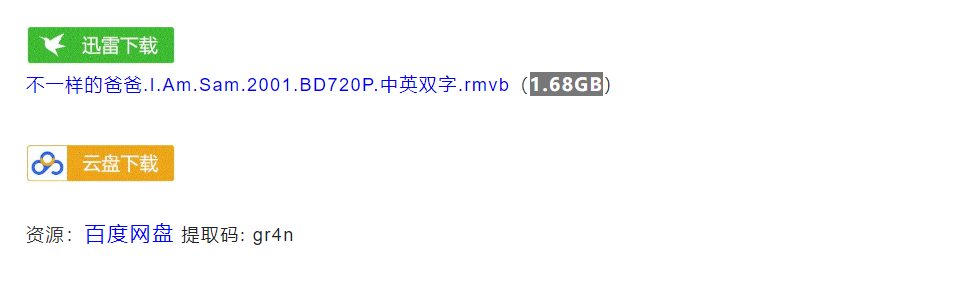
最后爬取的样式这样的。我选择的是txt文档的存储的。 
描述,电影的链接的地址和海报都有了。是不是非常happy呢。
还有两个待解决的问题。 1.不是xpath不能够完全匹配的问题。比如 这个电影的爬下来的link是空的, 打开是有link的 
2.爬了60页左右网址拒绝访问了 
requests.exceptions.ConnectionError: HTTPConnectionPool(host='www.rrdyw.cc', port=80): Max retries exceeded with url: /movie/2020/0607/10770.html (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x00000236459B4AC8>: Failed to establish a new connection: [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。',))
好吧就写道这里了。记录一下。
本文由
xujun20200616
原创发布于
阳光沙滩
,未经作者授权,禁止转载

 一日就是一天 回复 @Archer
一日就是一天 回复 @Archer