全部 文章 问答 分享 共找到165个相关内容
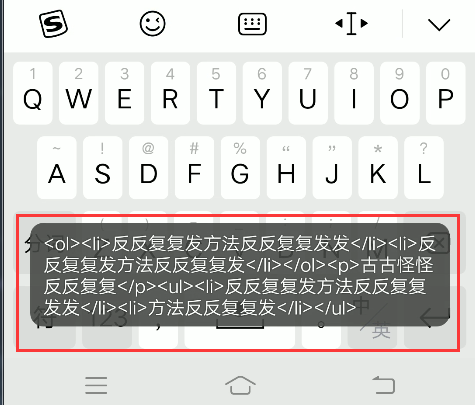
[文章] Android富文本编辑器,webview中提取HTML代码,去标签获得纯文字
问题:webview中html内容提取纯文字。富文本编辑器中,要读取html内容,想要获得输入文字的个数,html中有各种标签,有图片,有视频音频等,怎么提取纯文字呢。



[文章] Xpath介绍和使用
为什么学习XPATHXPath是一门在Html页面中查找信息的语言。XPath可用来在html页面中对元素和属性进行遍历。

[文章] Python 网络爬虫练手
,base_url):link=Nonehtml_elem=etree.HTML(html)url=html_elem.xpath('//div[@class="pagea"]/li

[文章] Python自动化测试之途牛网机票查询二(完结)
(driver).move_to_element(airTicketsMenu).perform()sleep(2)#点击出境·中国港澳台driver.find_element_by_xpath('/html
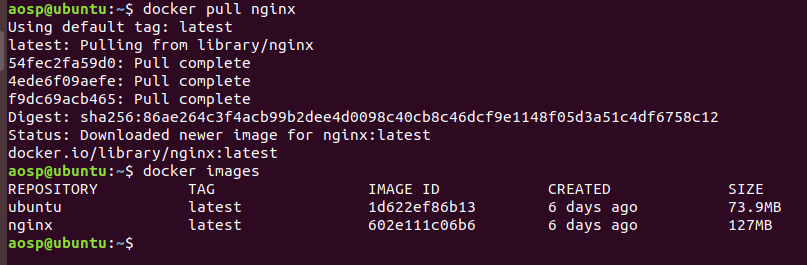
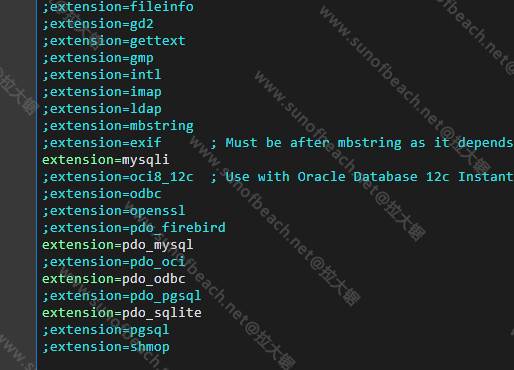
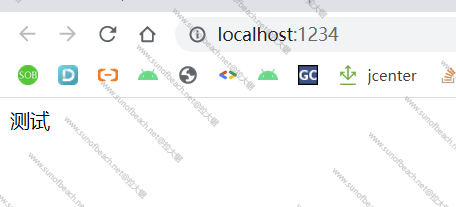

[文章] Android 性能分析工具Simpleperf简单使用
Android/sdk/ndk/23.1.7779620/simpleperfpython3app_profiler.py-pcom.hulian.newos默认10s结束,执行完成后需要拉取数据,有2种方式1,html

[文章] docker使用Nginx配置https访问
nginx/nginx.conf-v/home/docker/nginx/ssl:/etc/nginx/ssl-v/home/docker/nginx/wwwroot:/usr/share/nginx/html-v

[问答] 阳光沙滩APP,处理文本中的表情,大家是什么方案呢?
>
我看这个表情是html
2022-02-26 14:57
·
Android

[文章] 【学习笔记】【领券联盟】前端(Nuxt.js)——11.设置首页的分类点击事件
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域域名: 主域名不同http://www.baidu.com/index.html-->http://www.sina.com

[文章] 安装了VMware Tools,但无法实现文件的拖拽和复制粘贴---解决方案
安装了VMwareTools,但无法实现文件的拖拽和复制粘贴---解决方案参考文章:https://www.cnblogs.com/zhouzhihao/p/16486787.html
[文章] Python自动化测试之途牛网机票查询
url)driver.maximize_window()driver.implicitly_wait(20)sleep(5)#点击机票按钮driver.find_element_by_xpath('/html
