初始Python之Selenium操作浏览器(二)
上一讲,我们装好了相关驱动并进行了简单的测试,这次我们来学习Selenium新的方法。
前言
流程很简单:获取到页面元素 -> 操作元素
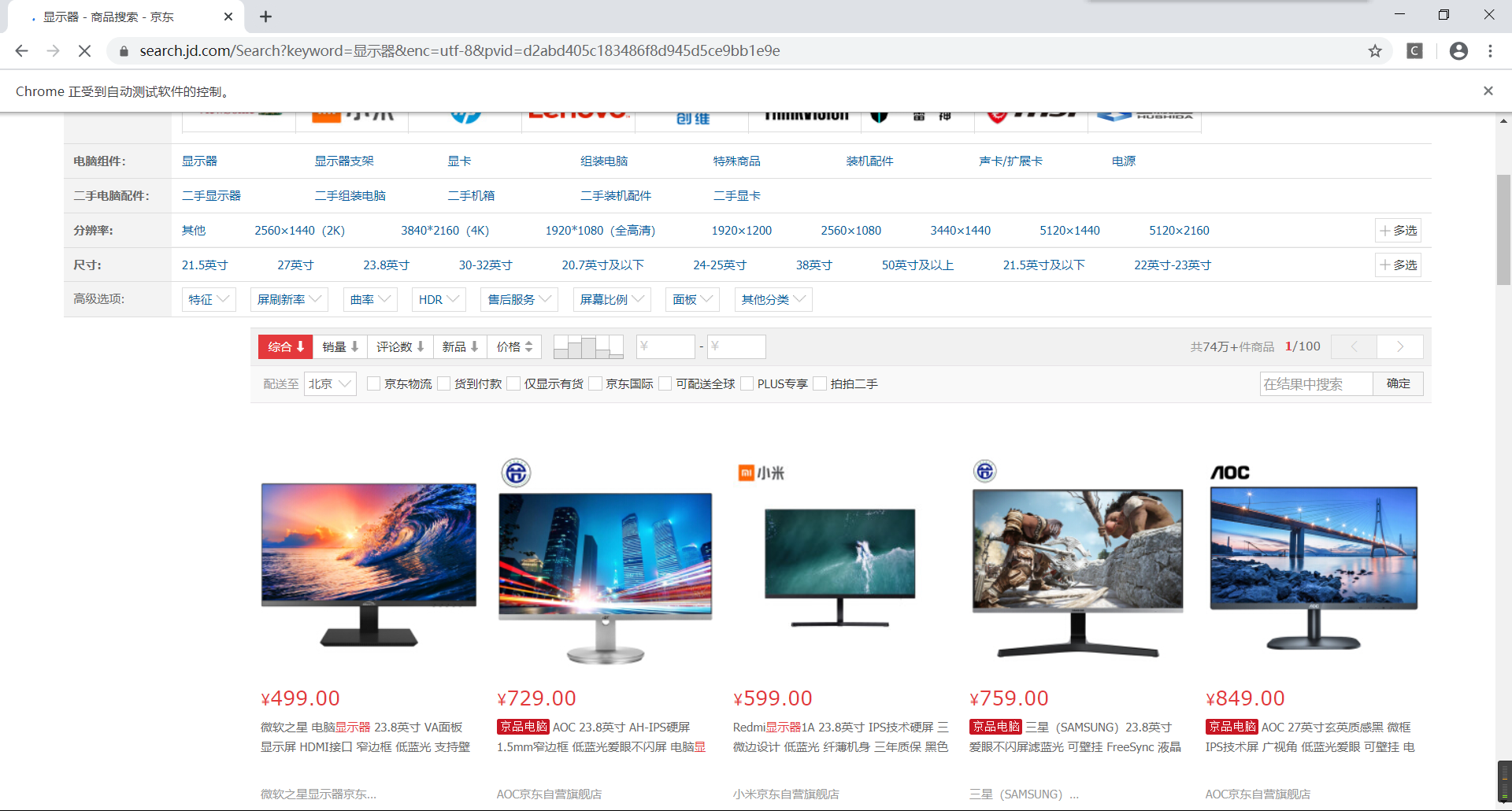
效果图
Python代码
from selenium import webdriver
# 因为我们需要用到强制等待时间,所以需要导入time模块
from time import sleep
url = "https://www.jd.com/"
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.maximize_window()
driver.get(url)
# 强制等待3秒,防止页面元素未加载完毕
sleep(3)
# find_element_by_id:通过id查找页面元素 send_keys:将文本输入到文本框
driver.find_element_by_id("key").send_keys("显示器")
# find_element_by_xpath:通过xpath路径查找元素(相对路径/绝对路径) click:模拟用户鼠标点击该元素
driver.find_element_by_xpath('//*[@id="search"]/div/div[2]/button').click()
# 5秒后退出浏览器
sleep(5)
driver.close()
大家应该都知道网页元素的id,但是xpath是个什么鬼???
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
想了解xpath更多信息的同学请进入xpath百度百科传送门。
接下来大家可能会问了,我还得去学习xpath语法?哈哈哈,其实duck不必,在浏览器中是可以直接复制元素的xpath路径的,下面我们以Google浏览器为例进行讲解。
- 首先,按F12快捷键(Ctrl+Shift+ i 也行)
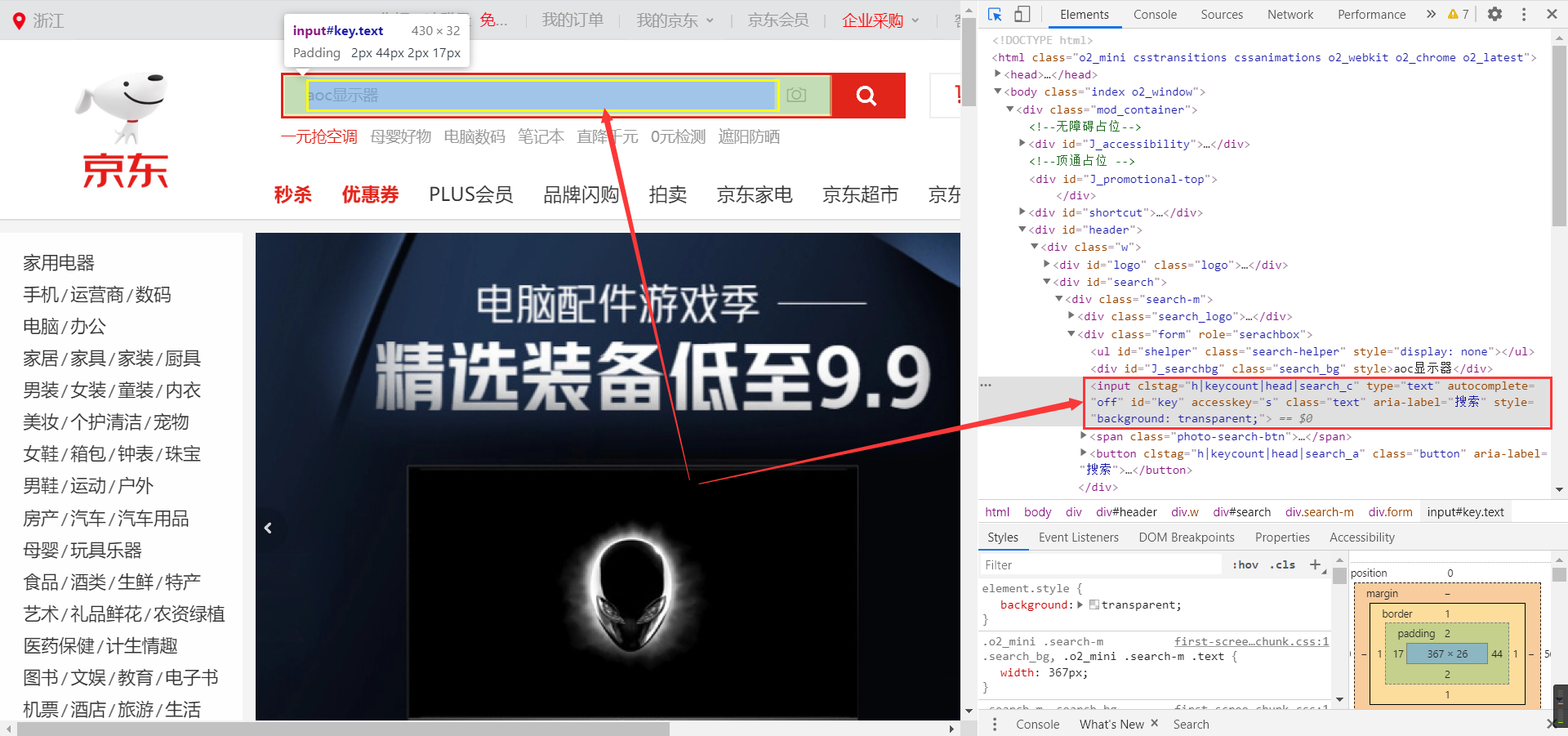
- 然后,点击控制台最左边的箭头图标(快捷键:Ctrl+Shift+C),再点击你要选择的元素,比如输入框,当然,您也可以一级一级的定位到某个元素。
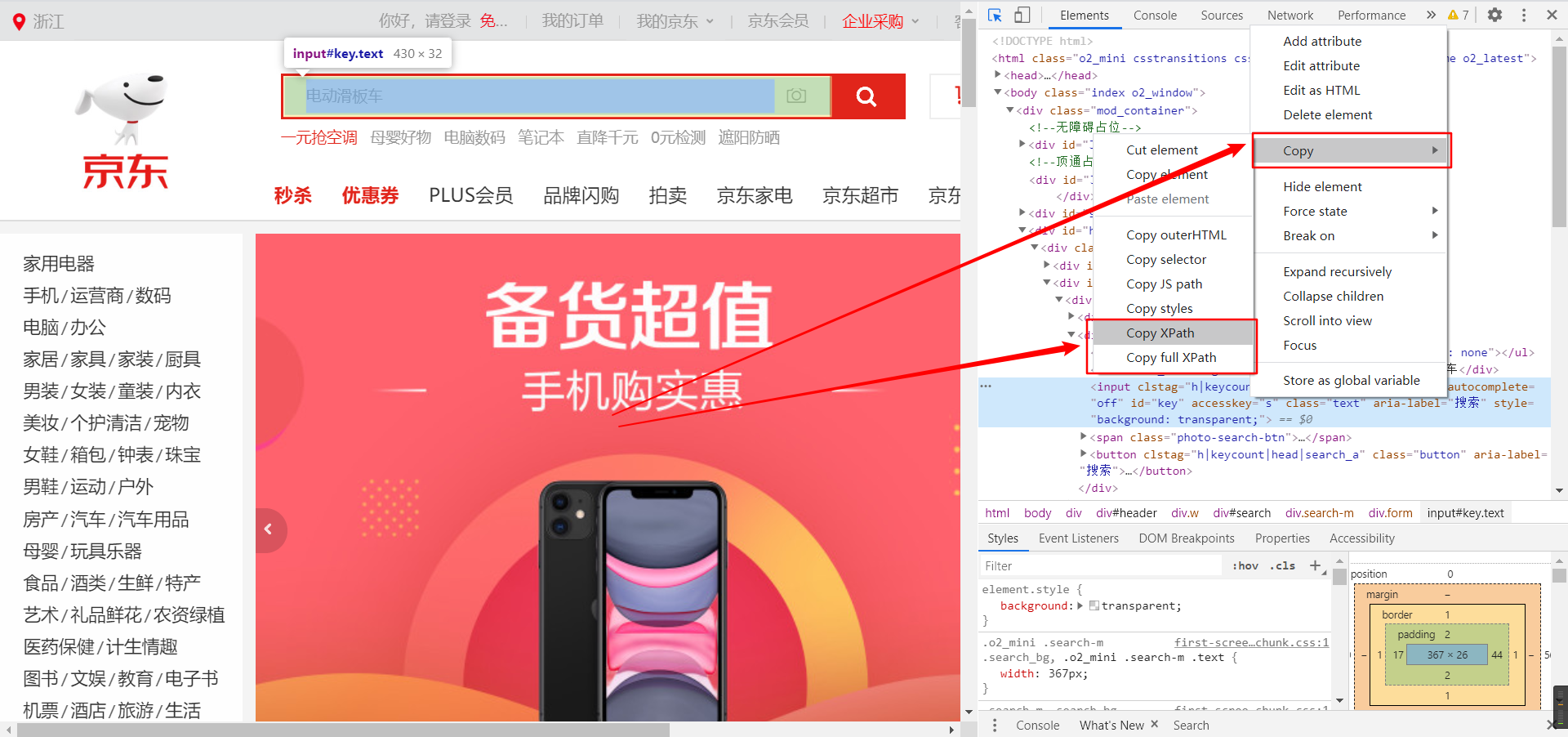
- 点击鼠标右键,依次选择“Copy” -> “Copy XPath”(“Copy full XPath”也是可以的)。
写在后面
好的,这样我们就将元素的xpath路径获取到了,是不是很简单呢?
点个赞再走呗~
~~小声BB:康师傅答应过要给我20个Sounf币来着~~


 A lonely cat 回复 @ncayu618
A lonely cat 回复 @ncayu618 
 拉大锯 回复 @xujun20200616
拉大锯 回复 @xujun20200616 



























